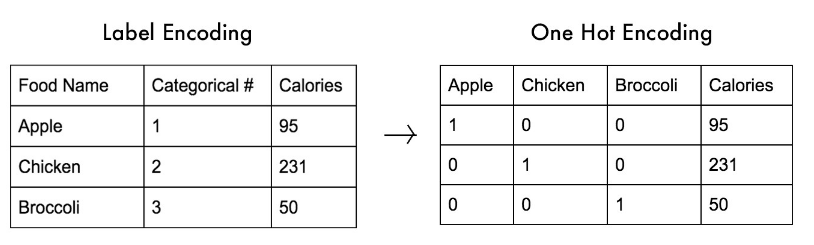
import pandas as pd # 예제 실행을 위해 데이터 프레임 생성 df = pd.DataFrame({'Employee ID':[111, 222, 333, 444], 'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'], 'Salary [$/h]':[35, 29, 38, 20], 'Years of Experience':[3, 4 ,9, 1]}) # 판다스는 반복문 필요없이 알아서 데이터(행)를 찾아준다. df['Years of Experience'] >= 3 0 True 1 True 2 True 3 False Name: Years of Experience, dt..