반응형
< 머신러닝으로 할 수 있는 것 >
- 편지봉투에 손으로 쓴 우편번호 숫자 자동 판별
- 의료 영상 이미지에 기반한, 종양 판단
- 의심되는 신용카드 거래 감지
- 블로그 글의 주제 분류
- 고객들을 취향이 비슷한 그룹으로 묶기
< 문제와 데이터 이해하기 >
- 가지고 이는 데이터가 내가 원하는 문제의 답을 가지고 있는가?
- 내 문제를 가장 잘 해결할 수 있는 머신러닝 방법은 무엇인가
- 문제를 풀기에 충분한 데이터를 모았는가?
- 머신러닝의 성과를 어떻게 측정할 것인가
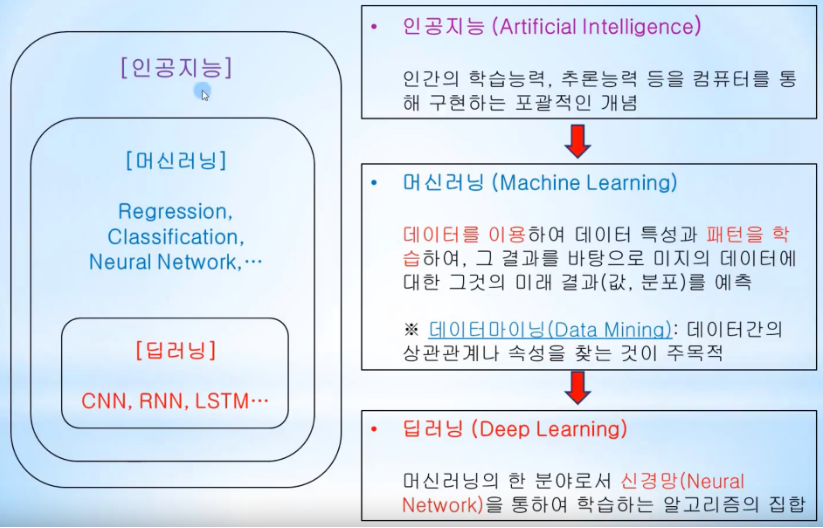
< 용어 및 설명 >
레퍼런스 : https://www.youtube.com/watch?v=KDrys0OnVho
< 머신러닝 : Supervised , Unsupervised >

< Supervised Learning >
우리는 Iris꽃의 꽃잎의 길이와 넓이, 꽃받침의 길이와 넓이 데이터를 가지고 있다. 이 데이터들을 가지고, Iris 꽃 (붓꽃) 의 품종을 분류할 수 있는 분류기를 만든다.
따라서, 새로운 꽃잎의 길이와 넓이, 꽃받침의 길이와 넓이에 대한 데이터를 입력하면, 이 붓꽃이 어떤 품종인지 분석이 가능하다.
이렇게 분류할 수 있는 분류기(classifier) 를 만들기 위해서는 데이터가 필요하며,
학습을 하기 위해서는, 데이터 뿐만 아니라, 품종이라는 결과를 학습 시키기 위해서, 데이터와 매핑된 품종 데이터도 함께 필요하다.
즉, 품종에 대한 데이터를 Lable 이라고 한다. 즉 이러한 레이블이 있는 데이터를 학습시키는 것이 지도학습이다.
레이블을 가지고 학습시키는 방법을 지도 학습 (Supervised Learning) 라고 한다.
< Regression(회귀) 과 Classification(분류) >
Regression
- 예 ) 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득을 예측하는 것
- 예 ) 옥수수 농장에서 전년도 수확량과 날씨, 고용 인원수 등으로 올해 수확량을 예측하는 것
Classifiation
- 예) 웹사이트가 어떤 언어로 되어있는가
- 예) 사진을 보고, 고양이 인지 강아지 인지, 소인지 분류
< Training 과 Test>
- 훈련이란, 데이터를 입력하고, 그 결과인 레이블이 나오도록 만드는 과정.
즉, 데이터와 레이블을 통해 학습을 시키는 과정
- 테스트란, 학습이 완료된 분류기에, 학습에 사용하지 않은 데이터를 넣어서, 정답을 맞추는지 확인하는 작업
< Generalization (일반화) >
- 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화되었다고 함.
< Overfiting (과대적합) / Underfitting (과소적합) >
- 오버핏팅이란 학습한 결과과, 학습에 사용된 데이터와 거의 일치하여, 새로운 데이터가 들어왔을 때, 예측이 틀려 버리는 상태
- 새로운 데이터에 일반화되기 어렵다.
- 언더핏팅은, 그 반대다.

< 성능 측정 >
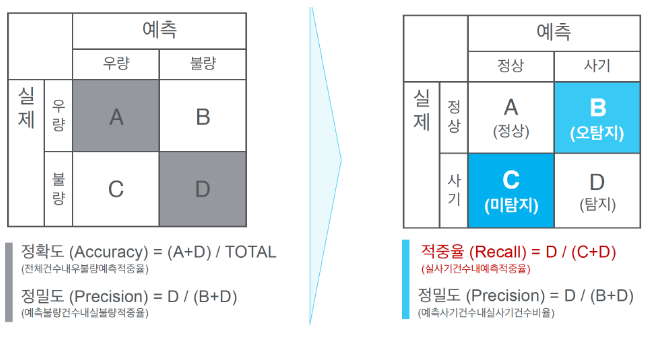
다음 게시글에서 계속
728x90
반응형