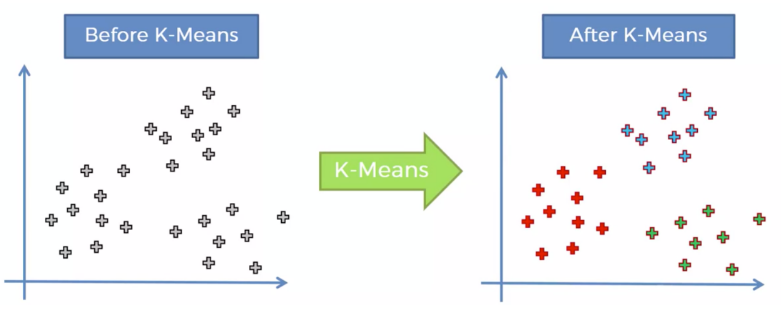
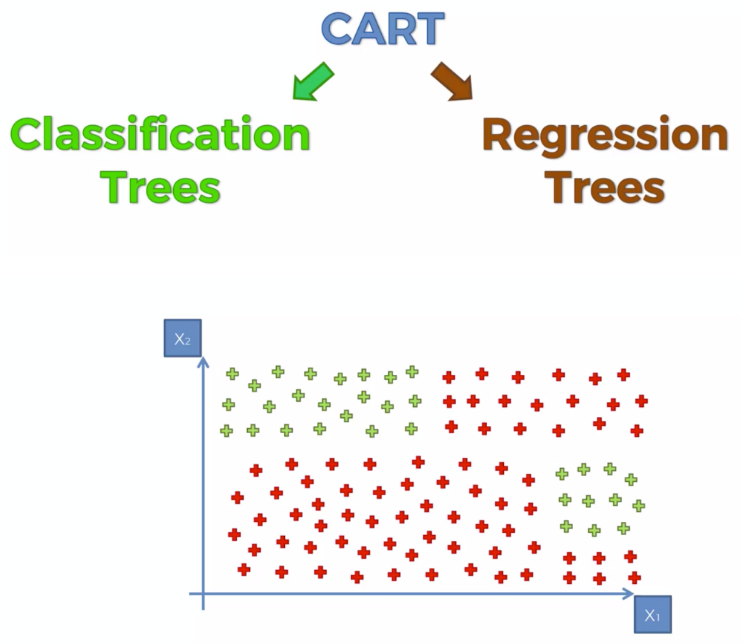
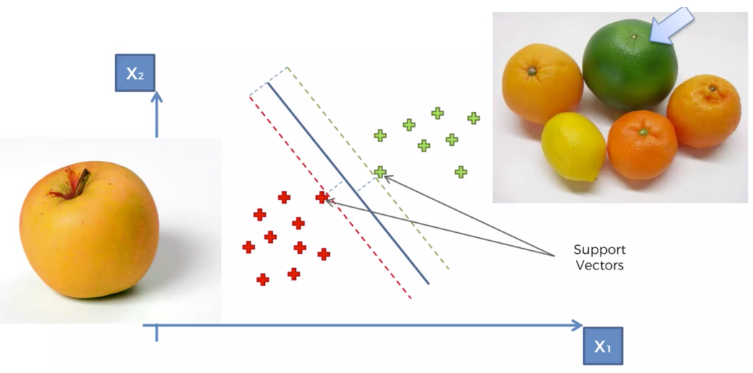
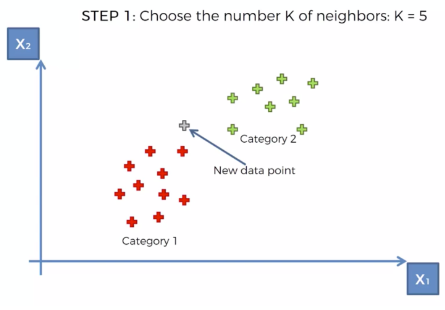
티처블 머신(Teachable Machine) ># 티처블 머신(Teachable Machine)은 구글이 개발한 웹 기반의 머신러닝 플랫폼 # 이 플랫폼은 사용자가 간단한 인터페이스를 통해 이미지, 음성 또는 동작과 같은 데이터를 입력하고, 이를 기반으로 모델을 학습시킬 수 있고, 사용자는 이를 통해 기계에게 어떤 입력이 어떤 출력을 가져오는지를 가르칠 수 있다.# https://teachablemachine.withgoogle.com/ Teachable MachineTrain a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, ap..