
< PANDAS OPERATIONS >
import pandas as pd
# 예제 실행을 위해 데이터 프레임 생성
df = pd.DataFrame({'Employee ID':[111, 222, 333, 444],
'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'],
'Salary [$/h]':[35, 29, 38, 20],
'Years of Experience':[3, 4 ,9, 1]})

< 경력이 3년 이상인 사람의 데이터를 가져오시오. >
# 판다스는 반복문 필요없이 알아서 데이터(행)를 찾아준다.
df['Years of Experience'] >= 3
0 True
1 True
2 True
3 False
Name: Years of Experience, dtype: bool
# True인 데이터(행)를 가져와라
# 1) df.loc
# 열자리에 : 은 생략해도됨
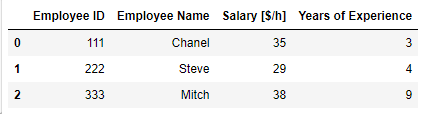
df.loc[ df['Years of Experience'] >= 3 , : ]
# 2) df.iloc
# iloc는 인덱스를 기준으로 동작되기 때문에, 특정 범위의 데이터를 가져오는것이 어렵다.
# 이런 문제의 경우에는 iloc 보다는 loc를 사용하는것이 더 효율적이다.
df.iloc[ df['Years of Experience'] >= 3 , : ]
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
Cell In[8], line 1
----> 1 df.iloc[ df['Years of Experience'] >= 3 , : ]
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\core\indexing.py:1147, in _LocationIndexer.__getitem__(self, key)
1145 if self._is_scalar_access(key):
1146 return self.obj._get_value(*key, takeable=self._takeable)
-> 1147 return self._getitem_tuple(key)
1148 else:
1149 # we by definition only have the 0th axis
1150 axis = self.axis or 0
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\core\indexing.py:1652, in _iLocIndexer._getitem_tuple(self, tup)
1651 def _getitem_tuple(self, tup: tuple):
-> 1652 tup = self._validate_tuple_indexer(tup)
1653 with suppress(IndexingError):
1654 return self._getitem_lowerdim(tup)
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\core\indexing.py:940, in _LocationIndexer._validate_tuple_indexer(self, key)
938 for i, k in enumerate(key):
939 try:
--> 940 self._validate_key(k, i)
941 except ValueError as err:
942 raise ValueError(
943 "Location based indexing can only have "
944 f"[{self._valid_types}] types"
945 ) from err
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\core\indexing.py:1540, in _iLocIndexer._validate_key(self, key, axis)
1538 if hasattr(key, "index") and isinstance(key.index, Index):
1539 if key.index.inferred_type == "integer":
-> 1540 raise NotImplementedError(
1541 "iLocation based boolean "
1542 "indexing on an integer type "
1543 "is not available"
1544 )
1545 raise ValueError(
1546 "iLocation based boolean indexing cannot use "
1547 "an indexable as a mask"
1548 )
1549 return
NotImplementedError: iLocation based boolean indexing on an integer type is not available
< 경력이 3년 이상인 사람의 이름과 시급정보를 가져오시오. >

df['Years of Experience'] >= 3
0 True
1 True
2 True
3 False
Name: Years of Experience, dtype: bool
# 경력이 3년 이상인 행의, 열 컬럼을 골라서 가져와라.
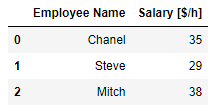
df.loc[ df['Years of Experience'] >= 3 , ['Employee Name','Salary [$/h]'] ]
< 경력이 4년 이상 8년 이하인 사람의 데이터를 가져오시오. >
# 판다스는 조건문 if 를 사용하지 않고, 기호로 사용해서 연산한다. and(&) , or (|)
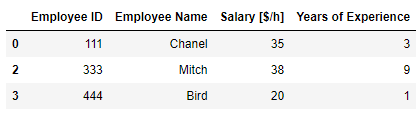
df.loc[(df['Years of Experience'] >= 4) & (df['Years of Experience'] <= 8), : ]

< 시급이 25달러 이하거나 35달러 이상이 사람의 데이터를 가져오시오 >
# 조건문을 사용하여 원하는 데이터 호출
(df['Salary [$/h]'] <= 25) | (df['Salary [$/h]'] >= 35)
0 True
1 False
2 True
3 True
Name: Salary [$/h], dtype: bool
# 원하는 데이터를 가져오기
df.loc[ (df['Salary [$/h]'] <= 25) | (df['Salary [$/h]'] >= 35) , : ]
< 시급이 가장 높은 사람은? >
# (1) .max를 사용하는 방법
df['Salary [$/h]'].max()
38
df['Salary [$/h]'] == df['Salary [$/h]'].max()
0 False
1 False
2 True
3 False
Name: Salary [$/h], dtype: booldf.loc[ df['Salary [$/h]'] == df['Salary [$/h]'].max() , : ]
