
< 데이터를 삭제하는 방법 >
# 행 삭제, 열 삭제
# drop() 함수를 이용하고, axis 만 설정해 주면 된다.
# 이전장에서 사용했던 데이터를 그대로 가져와서 진행

# store 2 삭제 (행)
df.drop('store 2' , axis= 0)

# glasses 컬럼 삭제 (열)
df.drop('glasses', axis=1)
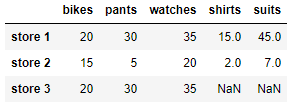
# pants, glasses, shirts 3개 컬럼 삭제
df.drop(['pants','glasses','shirts'] , axis=1)
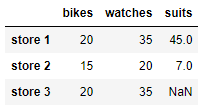
< 실제 삭제한 데이터 결과를 저장하는 방법 >
# 1) '=' 기호를 사용하여 데이터를 다시 저장하는 방법
df = df.drop('glasses' , axis=1)
ㄴ 삭제한 결과값을 df 원본에 다시 저장
# 2) inplace= True 함수(파라미터)를 사용하여 바로 저장
df.drop('watches' , axis=1 , inplace=True)
ㄴ 'watches' 열을 원본에서 바로 삭제하고 그대로 저장함
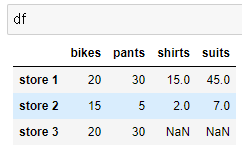
< 인덱스 이름, 컬럼 이름을 변경하는 방법 >
# rename 함수 : 인덱스명을 바꾸는 방법 store 3를 last store 로 변경 = .rename(index={}) 사용
df.rename( index= { 'store 3' : 'last store' }, inplace=True)
ㄴ 인덱스명은 {} 딕셔너리를 사용하여 정의함! 함수의 규칙같은것으로 외워야함!

# 컬럼명 변경 : bikes => hat , suits => shoes = .rename(columns={}) 사용
df.rename( columns= { 'bikes' : 'hat' , 'suits' : 'shoes' }, inplace=True)
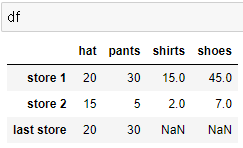
< 새로운 컬럼 생성 및 인덱스로 타입 변경 방법 >
# 새로운 컬럼 name 을 만들되, A, B, C 라고 넣자
df['name'] = ['A','B','C']
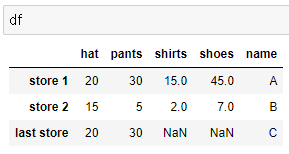
# 새로 넣은 name(컬럼) A, B, C 를 인덱스로 변경하고 싶다면 .set_index() 를 사용 (갈아끼기)
df.set_index('name', inplace=True)

# 인덱스로 넣었던 name을 다시 컬럼으로 바꾸고 싶다면 .reset_index() 사용 !!! 자주 사용하니까 알아둘것 !!!
df.reset_index(inplace=True)

다음 게시글에서 계속
'PYTHON LIBRARY > Pandas Library' 카테고리의 다른 글
| Python Pandas 카테고리컬 데이터 다루기 : groupby() , agg(), value_counts() 함수 활용 (0) | 2024.04.12 |
|---|---|
| Python Pandas로 결측치 데이터 처리하기: NaN 처리 isna(), notna(), dropna(), fillna() (0) | 2024.04.11 |
| Python Pandas로 데이터 다루기 : 데이터 액서스 .loc, .iloc 및 기본 인덱싱 방법 (0) | 2024.04.09 |
| Python Pandas로 데이터 분석 시작하기 : DataFrame 기초 (0) | 2024.04.09 |
| Python Pandas로 데이터 처리하기 : 시리즈의 레이블 접근과 산술 연산 (0) | 2024.04.08 |