< 데이터 프리프로세싱(Data Preprocessing) >
머신러닝 모델을 학습시키기 전에 데이터를 정제하고 준비하는 과정이 과정은 데이터의 품질을 향상시키고, 머신러닝 모델의 성능을 향상시키기 위해 필수적
< 순서 >
데이터를 분석하여 어떻게 데이터를 분리할지 인코딩을 할지 확인 후,
1) NaN 처리
2) X, y 데이터 분리 : 학습할 변수와 레이블링 변수로 분리
2) 문자열 데이터 인코딩 : 원-핫 인코딩, 레이블 인코딩 등의 방법을 사용
3) 특성 스케일링 : 표준화(Standardization)나 정규화(Normalization) 등의 방법을 사용
4) 데이터셋을 Training 용과 Test 용으로 나눈다.
< 예제를 통해 실제 데이터 프리프로세싱 연습 >
import library
# Data Preprocessing Template
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
< import the dataset >
# 실습용 데이터로 실행
df = pd.read_csv('../data/Data.csv')
df
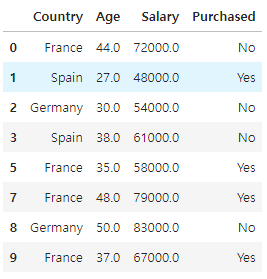
ㄴ 데이터 분석
# 출생 지역과 나이 연봉에 따른 구매의사 결정 여부에 대한 데이터이다.
# 즉 'Country' , 'Age', 'Salary'에 따라 'Purchased' 가 정해진다.
# 앞선 세가지의 평가 항목이 학습할 변수 X , 구매의사 결정 여부가 레이블링 변수 y로 미리 예측 할수 있다.
# 머신 러닝 학습을 위해 문자열 데이터의 갯수 우선 확인 ('Country' 와 'Purchased')
df['Country'].nunique()
3
# 알파벳 순으로 정렬하여 실제 데이터 확인
sorted( df['Country'].unique() )
['France', 'Germany', 'Spain']
df['Purchased'].nunique()
2
sorted( df['Purchased'].unique() )
['No', 'Yes']
< (1) NaN 처리 >
# NaN 데이터는 머신러닝 학습시 오류를 발생시키기때문에 처리가 필요
df.isna().sum()
Country 0
Age 1
Salary 1
Purchased 0
dtype: int64
1) 삭제 전략
df.dropna()

2) 채우는 전략
# 평균으로 채워보자 : 보통 데이터에 문자열이 포함된 경우가 많으므로 평균을 구할때는 numeric_only = True 꼭 사용
df.fillna ( df.mean(numeric_only= True) )

## 예제에서는 삭제 전략으로 실행해보자
# 삭제하여 데이터에 바로 반영
df.dropna(inplace=True)
# 빈칸이 없는지 확인
df.isna().sum()
Country 0
Age 0
Salary 0
Purchased 0
dtype: int64< (2) X, y 데이터 분리 : 즉 학습할 변수와 레이블링 변수로 분리 >

# 해당 데이터에서 앞에 데이터를 분석하여 결론적으로 'Purchased' 구매의사를 결정하므로
# X 데이터(학습할 변수)가 Country, Age, Salary // Y 데이터(레이블링 변수)가 Purchased
# Y데이터 우선 설정
# 1차원 데이터이므로 소문자로 표시 (1차원 벡터)
y = df['Purchased']
y
0 No
1 Yes
2 No
3 No
5 Yes
7 Yes
8 No
9 Yes
Name: Purchased, dtype: object
# X 데이터 설정
# 2차원 데이터이므로 대문자로 표시 (2차원 메트릭스(행,렬))
X = df.loc[ : , 'Country' : 'Salary' ]
X

< 데이터를 확인해 보니, 컴퓨터가 이해할 수 있도록 바꿔야 한다 >
컴퓨터는 숫자로 처리한다.
숫자가 아닌 데이터 중에서, 카테고리로 판단되는 데이터는, 숫자로 바꿔줄 수 있다.
# 문자열 컬럼의 유니크 갯수를 확인한다. (카테고리컬 데이터 확인)
# 갯수가 2개이면, 0과 1로만 바꿔도 되니까, 이때는 '레이블 인코딩'만 사용하면 된다.
# 하지만 갯수가 3개 이상이면, '원-핫 인코딩'을 사용하여, 0과 1로 표현가능하도록 변경 한다.
# Country 갯수는 3개 이므로 원-핫 인코딩을 사용해야 한다.
X['Country'].nunique()
3
# 스펠링별로 값의 위치를 정하기 위해 정렬을 꼭 실행해줘야 한다.
sorted(X['Country'].unique())
['France', 'Germany', 'Spain']
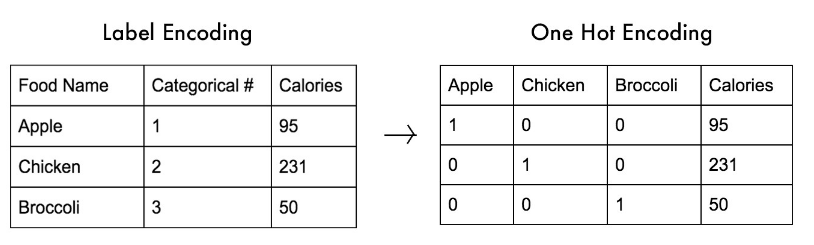
# 이렇게 1대1로 매칭하는걸 'Label encoding : 레이블 인코딩'
# 'France' => 0
# 'Germany' => 1
# 'Spain' => 2
# but, 숫자가 0,1 이외 숫자가 나오면 학습에 오류가 날수있다.
# 그러므로 두개일 경우에만 레이블이 유용하고 그이상부터는 원-핫 인코딩을 사용하는게 오류를 줄일수 있다.
# 1과 0으로만 구성하게 만드는게 'One Hot Encoding : 원-핫 인코딩'
# 정렬된 순서대로 해당 항목이 출력될때 1을 대입한다.
# 하단 데이터를 예시로
# France Germany Spain Age Salary
# 0. 1 0 0 44 72000
# 1. 0 0 1 27 48000
# 2. 0 1 0
# 3. 0 0 1
# 이렇게 만들면 컴퓨터 성능, 학승 성능이 좋아진다.

< (3) 실제 인코딩을 해보자 >
# 우선 임포트
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
# 1) 레이블 인코딩 하는 방법
# encoder 변수로 저장하여 사용
encoder = LabelEncoder()
X['Country'] = encoder.fit_transform( X['Country'] )

ㄴ Country 열이 0,1,2로 인코딩 된걸 볼수있다. but 컴퓨터에선 0,1로만 구성된값이 가장 이상적인 값이므로 해당 예시에선 원-핫 인코딩이 더 알맞다.
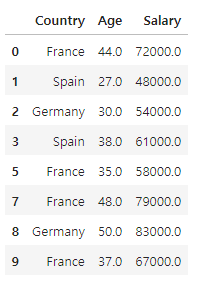
# 레이블 인코딩한 결과를 다시 복구
X = df.loc [ : , 'Country' : 'Salary' ]
X
# 2) 원 핫 인코딩 하는 방법
# ColumnTransformer([('encoder' (문자열 아무거나 적어도됨 for 문의 변수명 처럼), OneHotEncoder(), [0] )] 사용
# ct 라는 변수로 지정하여 사용
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0] )] , remainder= 'passthrough' )
ㄴ [0] 이라고 쓴 이유?? X에 들어있는 원-핫인코딩 하고 싶은 컬럼의 인덱스
ㄴ 예를 들어, 원핫 인코딩 하고 싶은 컬럼이, 첫번째랑 세번째 컬럼이면 => [0,2] 로 작성하면 됨
ㄴ remainder= 'passthrough' 나머지 부분은 변형하지 말고 통과시키라는 뜻
X = ct.fit_transform( X )

ㄴ Numpy 형태로 결과값이 출력된다. 머신러닝은 numpy로 처리하기 때문
## y 레이블링 변수 인코딩
y.nunique()
2
# y는 갯수가 2개이므로 레이블링 인코딩으로 처리
# 인코딩전 정렬
sorted(y.unique())
['No', 'Yes']
y = encoder.fit_transform(y)
y
array([0, 1, 0, 0, 1, 1, 0, 1])
# 이제 X 와 y 를 모두 숫자로 바꾸었다.
# 이제 범위를 맞춰주는 피쳐 스케일링이 필요하다.