
< Dealing with NaN >
# We create a list of Python dictionaries
# 실습전 데이터 프레임에 사용할 item2 변수 생성
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
# 비어있는 데이터를 어떻게 처리할 것인가???
df = pd.DataFrame(data= items2, index= ['store 1','store 2','store 3'])
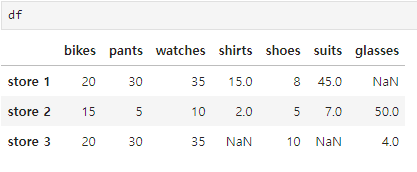
# 비어있는 데이터 (결측치) 가 어디에 몇개나 있는지 확인
# .isna() 비어있니?
df.isna()

# .notna() 채워져 있니?
df.notna()

< isna 활용 >
# Pandas 에서는 sum 함수 사용시 컬럼 별로 더해준다.
df.isna().sum()
bikes 0
pants 0
watches 0
shirts 1
shoes 0
suits 1
glasses 1
dtype: int64
#반복하면 빈칸의 총합을 보여준다.
df.isna().sum().sum()
3< Nan을 처리하는 전략 >
# 1. 삭제하는 전략 => 빈칸이 포함된 데이터(행) 자체를 삭제한다
df.dropna()

# 2. 특정 값으로 채우는 전략 => 빈칸을 지정한 값으로 채운다.
df.fillna(0)
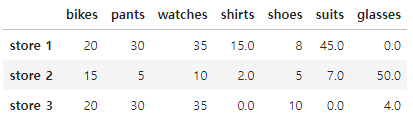
ㄴ 숫자 0 으로 지정하여 빈칸을 0 으로 출력
df.fillna('데이터 없음')

ㄴ 문자열 '데이터 없음' 으로 지정하여 빈칸을 '데이터 없음' 으로 출력
# 특정 열만 지정하여 빈칸을 채울수도 있음
df['shirts'].fillna(100)
store 1 15.0
store 2 2.0
store 3 100.0
Name: shirts, dtype: float64ㄴ 'shirts' 열에서 빈값을 100으로 채움
df['shirts'] = df['shirts'].fillna(100)

ㄴ 수정한 값을 실제 데이터 프레임에 저장
# ['suits','glasses'] 열에 빈칸을 0으로 채운후 데이터에 저장한다.
df[['suits','glasses']] = df[['suits','glasses']].fillna(0)

# 3.
# 비어있는 데이터를 채우되,
# 위행, 아래행의 데이터로 채우거나
# 왼쪽열, 오른쪽열의 데이터로 채우는 방법
# 단지정한 행,열에 데이터값이 없을경우 NaN으로 출력됨
# 데이터 프레임을 새로 지정하여 실습
df = pd.DataFrame(data = items2, index=['store 1','store 2','store 3'])
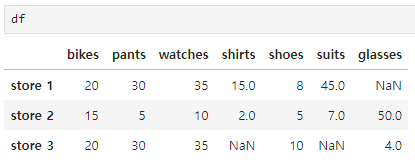
# 윗 행으로 채우는 방법
df.fillna( method= 'ffill' , axis=0 )

ㄴ 실행시 발생되는 에러는 추후 버전에서는 해당 명령어가 사라지므로 신규 함수로 사용하라는것
# 오류에 출력된 신규 함수 사용
df.ffill()

# 아래 행으로 채우는 방법
df.bfill()

# 좌측열 값으로 채워라
df.ffill(axis=1)
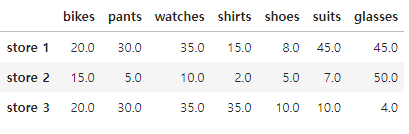
# 우측열 값으로 채워라
df.bfill(axis=1)

# fillna와 연산 함수를 활용하여 최대값, 평균값 등 원하는 값으로 채울수도 있음
# ex) 빈칸을 그 컬럼의 평균값으로 채워라
df.fillna( df.mean() )

# 활용 함수의 예
max() : 최대값
min() : 최소값
std() : 표준편차
median() : 중앙값 (데이터를 오름차순 정렬한 후에, 가운데 위치한 값)
< 예제를 통해서 이전 데이터 프레임 관련 개념과 NaN 함수를 모두 활용 해보자 >
import pandas as pd
import numpy as np
# 책 제목과 작가, 그리고 유저별 별점 데이터가 있다.
books = pd.Series(data = ['Great Expectations', 'Of Mice and Men', 'Romeo and Juliet', 'The Time Machine', 'Alice in Wonderland' ])
authors = pd.Series(data = ['Charles Dickens', 'John Steinbeck', 'William Shakespeare', ' H. G. Wells', 'Lewis Carroll' ])
user_1 = pd.Series(data = [3.2, np.nan ,2.5])
user_2 = pd.Series(data = [5., 1.3, 4.0, 3.8])
user_3 = pd.Series(data = [2.0, 2.3, np.nan, 4])
user_4 = pd.Series(data = [4, 3.5, 4, 5, 4.2])
# np.nan values 는 해당 유저가 해당 책에는 아직 별점 주지 않은것이다.
# labels: 'Author', 'Book Title', 'User 1', 'User 2', 'User 3', 'User 4'.
# 아래 그림처럼 나오도록 만든다.
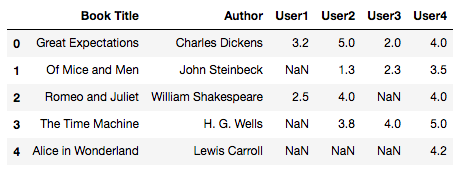
# 1. 데이터 프레임으로 가공할 딕셔너리를 만들고, 2. 데이터프레임으로 만든 후, 3. nan을 평균값으로 채운다.
# 1
data = { 'Book Title' : books , 'Author' : authors,
'User1' : user_1 , 'User2' : user_2 , 'User3' : user_3 , 'User4' : user_4 }
# 2
df = pd.DataFrame(data= data)

# 3
# 문자열이 데이터에 같이 있는 표에 숫자값만 평균을 구할때는 numeric_only=True 파라미터(함수)를 사용
df.mean(numeric_only=True)
User1 2.850000
User2 3.525000
User3 2.766667
User4 4.140000
dtype: float64
df.fillna(df.mean(numeric_only=True))

< Loading Data into a Pandas DataFrame >
# 데이터를 불러온후 몇가지 유용한 함수를 적용해 보자.
# 사전에 배포받은 .csv 사용
df = pd.read_csv('../data/GOOG.csv')
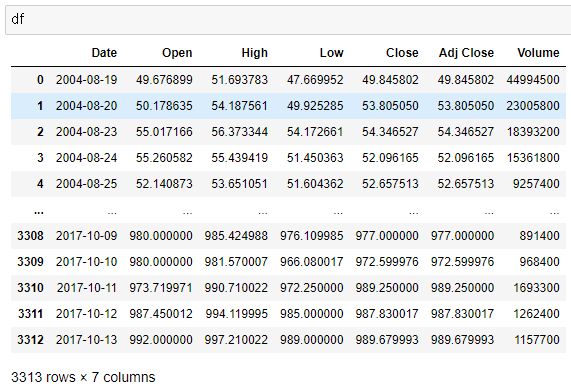
# 가장 상단의 데이터 5개를 보여줌 (갯수를 적으면 그 갯수 만큼 보여줌)
df.head(1)

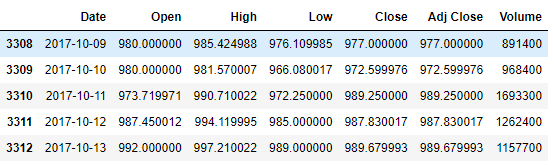
# 가장 하단에서부터 데이터를 보여줌 (기본적으로 5개, 갯수를 적으면 그갯수 만큼)
df.tail()
# 행,열의 개수를 튜플로
df.shape
(3313, 7)
# 각 컬럼별로 기초 통계 데이터를 보여준다. 문자열 데이터는 자동으로 빠진다.
df.describe()

ㄴ e+03 : 10의 3승 = 1000
ㄴ e-07 : 10의 마이너스 7승 = 0.0000001
# 데이터프레임의 전체적인 구조와 각 열(column)의 명칭과 데이터 타입
# 비어 있지 않은 데이터의 개수등을 보여줌
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3313 entries, 0 to 3312
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 3313 non-null object
1 Open 3313 non-null float64
2 High 3313 non-null float64
3 Low 3313 non-null float64
4 Close 3313 non-null float64
5 Adj Close 3313 non-null float64
6 Volume 3313 non-null int64
dtypes: float64(5), int64(1), object(1)
memory usage: 181.3+ KB
# 비어있는 데이터 확인
df.isna()

# 비어있는 데이터의 수 (비어있는 데이터가 없으면 깨끗한, 클린한 데이터라 칭함)
df.isna().sum()
Date 0
Open 0
High 0
Low 0
Close 0
Adj Close 0
Volume 0
dtype: int64
# 각 컬럼별 평균을 구하라.
df.mean(numeric_only=True)
ㄴ 문자열을 제외할때는 numeric_only=True 사용
Open 3.801861e+02
High 3.834937e+02
Low 3.765193e+02
Close 3.800725e+02
Adj Close 3.800725e+02
Volume 8.038476e+06
dtype: float64
# High 컬럼의 최대값 구하기.
df['High'].max()
997.210022
다음 게시글에서 계속
'PYTHON LIBRARY > Pandas Library' 카테고리의 다른 글
| Pandas Operations 예제 : 데이터 필터링과 분석 .loc(), .iloc(), 조건부 기호 &, | 활용 (0) | 2024.04.14 |
|---|---|
| Python Pandas 카테고리컬 데이터 다루기 : groupby() , agg(), value_counts() 함수 활용 (0) | 2024.04.12 |
| Python Pandas 데이터프레임 조작 : 행/열 삭제부터 이름/타입 변경까지 drop() 함수 , rename({}) 함수 (0) | 2024.04.10 |
| Python Pandas로 데이터 다루기 : 데이터 액서스 .loc, .iloc 및 기본 인덱싱 방법 (0) | 2024.04.09 |
| Python Pandas로 데이터 분석 시작하기 : DataFrame 기초 (0) | 2024.04.09 |