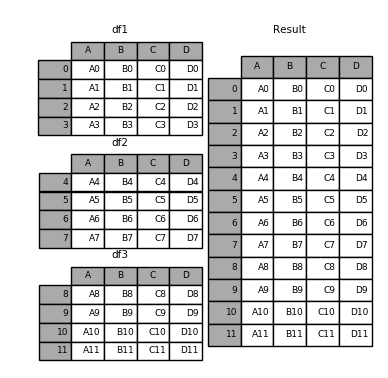
Reference: https://pandas.pydata.org/pandas-docs/stable/merging.html # 판다스를 활용하여 데이터끼리 연결과 병합을 해보자 # 우선 예제 실행에 필요한 데이터 프레임 세개를 생성하여 각각 df1, df2, df3 으로 메모리에 업로드 한다. df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}, index=[0, 1, 2, 3]) df2 = pd.DataFrame({'A': ['A4', 'A5', ..