
< SORTING AND ORDERING >
# 정렬할 데이터프레임을 먼저 생성하여 df 라는 변수명으로 저장
df = pd.DataFrame({'Employee ID':[111, 222, 333, 444],
'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'],
'Salary [$/h]':[35, 29, 38, 20],
'Years of Experience':[3, 4 ,9, 1]})

< Values 값 정렬>
# 경력을 가지고 오름차순 정렬 => index가 아니라 values 로
df.sort_values('Years of Experience')

# 경력을 가지고 내림차순 정렬 ascending= False 를 컬럼명 뒤에 기재
# ascending 의 default 파라미터는 True인 상태인것을 추측 가능
# 즉 인덱스 혹은 벨류 값으로 기본 정렬을 시행할 경우 우선 오름차순으로 정렬된다.
df.sort_values('Years of Experience', ascending= False)
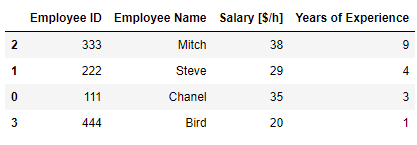
# 이름과 경력으로 정렬해주세요. 오름차순 정렬
df.sort_values( ['Employee Name','Years of Experience'] )
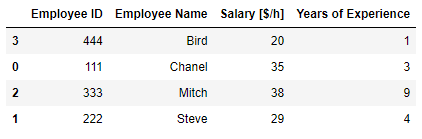
# 이름과 경력으로 정렬하되, 이름은 오름차순, 경력은 내림차순으로 정렬
# 컬럼 명을 원하는 순서대로 적고, ascending= 값도 순서대로 기재하여 주면 따로 적용 가능
df.sort_values( ['Employee Name','Years of Experience'] , ascending= [True, False])

< Index로 정렬 >
# index 오름차순
df.sort_index()

# index 내림차순
df.sort_index(ascending=False)

다음장에서 계속
'PYTHON LIBRARY > Pandas Library' 카테고리의 다른 글
| Pandas를 활용한 데이터 연결과 병합 : concat()과 merge()의 비교 (0) | 2024.04.14 |
|---|---|
| Pandas 데이터프레임 컬럼에 함수(문자열 전용 함수까지) 적용하기 : def와 apply() 사용법 (0) | 2024.04.14 |
| Pandas Operations 예제 : 데이터 필터링과 분석 .loc(), .iloc(), 조건부 기호 &, | 활용 (0) | 2024.04.14 |
| Python Pandas 카테고리컬 데이터 다루기 : groupby() , agg(), value_counts() 함수 활용 (0) | 2024.04.12 |
| Python Pandas로 결측치 데이터 처리하기: NaN 처리 isna(), notna(), dropna(), fillna() (0) | 2024.04.11 |