< Hierarchical Clustering >
- 데이터 포인트들을 계층적으로 그룹화하는 클러스터링 방법
- 복잡한 데이터 구조를 가진 데이터 세트에서 패턴이나 관계를 파악하는 데 유용
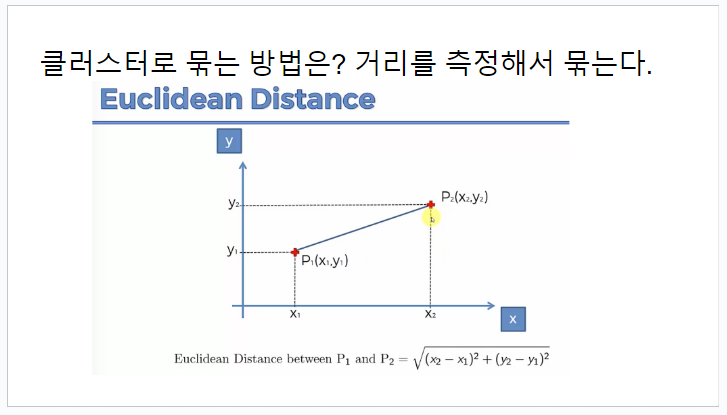
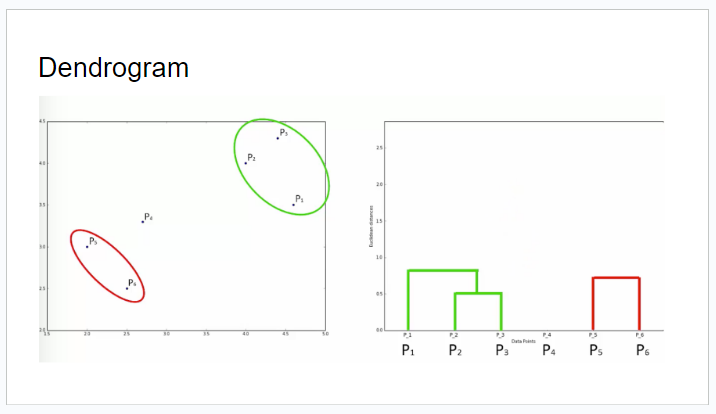
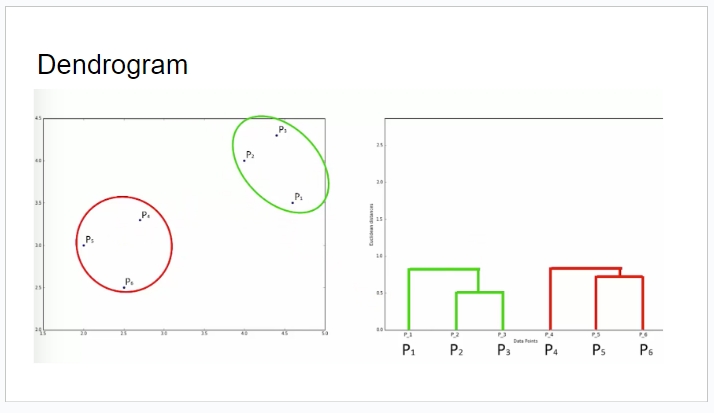
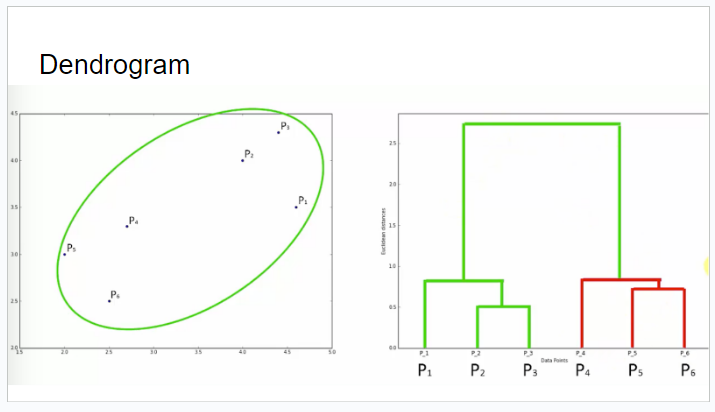
- Hierarchical Clustering의 결과는 트리 형태로 나타낼 수 있으며, 이를 덴드로그램(dendrogram)이라고 한다.
- 덴드로그램은 각 클러스터의 병합 순서와 유사도를 시각적으로 표현하고, 클러스터의 수를 사전에 지정할 필요가 없으므로, 클러스터의 개수를 자유롭게 선택할 수 있어 매우 유연하게 사용할 수 있다.




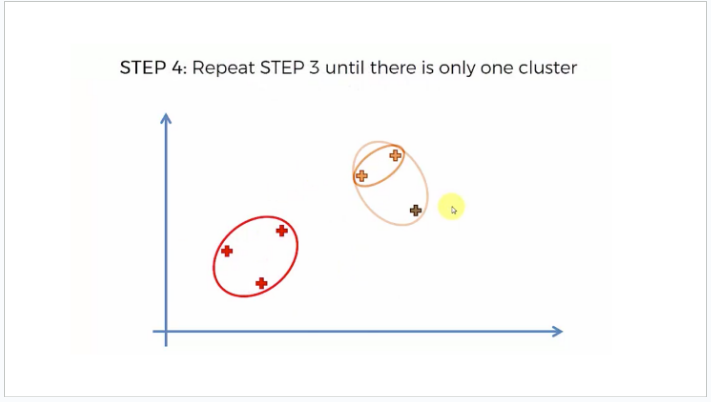
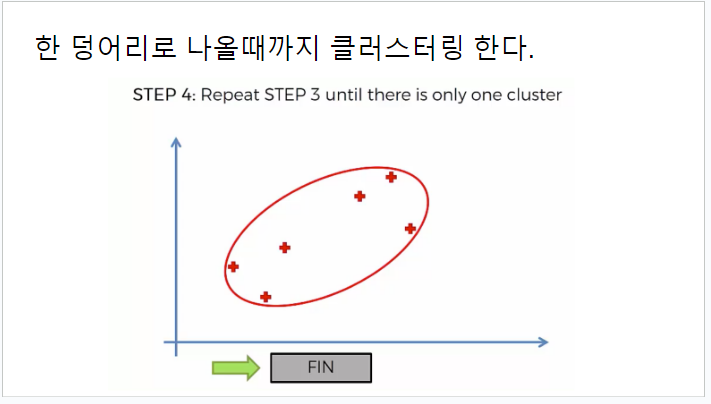
묶인 클러스터를 점 하나로 보고, 반복하여 가까운것끼리 묶는다.






< 예제문을 통해 실제 코딩해 보자 >
# Library 임포트
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# dataset 읽어오기
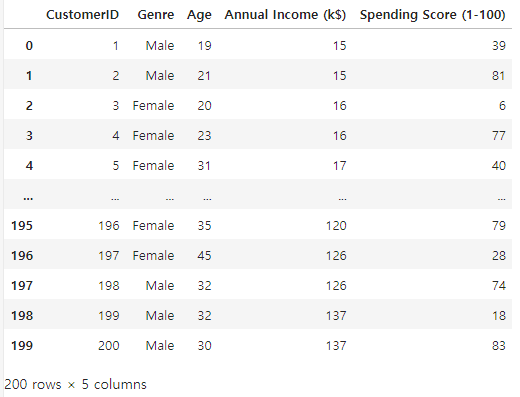
df = pd.read_csv('../data/Mall_Customers.csv')
df
# 비어있는셀 확인
df.isna().sum()
CustomerID 0
Genre 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64
# 클러스터링 이므로 X 데이터만 메모리에 업로드
X = df.iloc [ : , 1 : ]
X

# 문자열이 있으므로 인코딩 필요
# 2개니까 레이블 인코딩
X['Genre'].nunique()
2
X['Genre']
0 Male
1 Male
2 Female
3 Female
4 Female
...
195 Female
196 Female
197 Male
198 Male
199 Male
Name: Genre, Length: 200, dtype: object
from sklearn.preprocessing import LabelEncoder
# 변수로 저장할때 함수명 뒤에 () 빼먹지 말고 꼭 써서 저장해야 동작됨!!
encoder = LabelEncoder()
encoder.fit_transform( X['Genre'] )
array([1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1,
0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1,
0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0,
0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1,
0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0,
0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1,
1, 1])
# 인코딩된 데이터를 X 데이터에 다시 메모리 업로드
X['Genre'] = encoder.fit_transform( X['Genre'] )
X

< Dendrogram 을 그리고, 최적의 클러스터 갯수를 찾아보자. >
import scipy.cluster.hierarchy as sch
sch.dendrogram( sch.linkage(X , method= 'ward') )
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Distances')
plt.show()

ㄴ 대략 5개일 때가 가장 비율이 맞아 보인다. (좀더 기준치를 위로 올려서 4개로 해도되고 그건 개인 자유)
< Training the Hierarchical Clustering model >
# 이제 나눌 개수도 정하였으니 인공지능을 생성하여 학습시키고 예측을 시켜 보자.
from sklearn.cluster import AgglomerativeClustering
# K-Means 때와 동일하게 학습과 예측을 동시에 진행
hc = AgglomerativeClustering(n_clusters= 5)
hc.fit_predict(X)
array([4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3,
4, 3, 4, 3, 4, 0, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 0,
4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 1, 2, 1, 2, 1, 2,
0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 0, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2,
1, 2], dtype=int64)
# 예측정보 저장
y_pred = hc.fit_predict(X)
# 그룹분리된 갯수가 일정한지 확인하기위하여 원본데이터에 예측값을 신규 컬럼으로 삽입
df['Group'] = y_pred
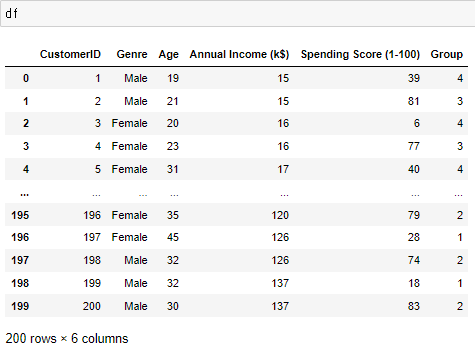
ㄴ 이제 원하는 그룹숫자인 행을 가져와서 데이터가 각각 몇개인지 구분할수 있다.