
# 기초개념에서 배운것들을 실습문제를 통해서 복습
뉴욕 airBnB : https://www.kaggle.com/ptoscano230382/air-bnb-ny-2019
DataUrl = ‘https://raw.githubusercontent.com/Datamanim/pandas/main/AB_NYC_2019.csv’
df= pd.read_csv('https://raw.githubusercontent.com/Datamanim/pandas/main/AB_NYC_2019.csv')
df

문제) 데이터의 각 host_name의 빈도수를 구하고 host_name으로 정렬하여 상위 5개를 출력하라
df['host_name'].value_counts().head()
host_name
Michael 417
David 403
Sonder (NYC) 327
John 294
Alex 279
Name: count, dtype: int64
문제) 데이터의 각 host_name의 갯수를 구하고 갯수 기준 내림차순 정렬한 데이터 프레임을 만들어라.
# 1차원 시리즈
df['host_name'].value_counts()
host_name
Michael 417
David 403
Sonder (NYC) 327
John 294
Alex 279
...
Rhonycs 1
Brandy-Courtney 1
Shanthony 1
Aurore And Jamila 1
Ilgar & Aysel 1
Name: count, Length: 11452, dtype: int64
# 데이터 프레임은 2차원 => .to_frame() 함수 사용
df['host_name'].value_counts().to_frame()
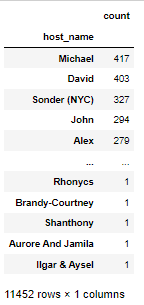
문제) neighbourhood_group의 값에 따른 neighbourhood컬럼 값의 갯수를 구하여라
df.shape
(48895, 16)
df['neighbourhood_group'].nunique()
5ㄴ 48895개의 데이터가 neighbourhood_group 기준으로 보면 다섯가지로 구분된다는것 그 각각 다섯가지가 몇개로 구성되어있는지 구해달라
# 네이버 후드 그룹(neighbourhood_group) 을 기준으로 같은 네이버 후드(neighbourhood)끼리 세어달라 => 그룸바이를 두개로 기재한다.
# 그룹바이도 여러개가 가능하다.
df.groupby( ['neighbourhood_group' , 'neighbourhood'] )['neighbourhood_group'].count()
neighbourhood_group neighbourhood
Bronx Allerton 42
Baychester 7
Belmont 24
Bronxdale 19
Castle Hill 9
..
Staten Island Tottenville 7
West Brighton 18
Westerleigh 2
Willowbrook 1
Woodrow 1
Name: neighbourhood_group, Length: 221, dtype: int64
문제) neighbourhood_group 값에 따른 price값의 평균, 분산, 최대, 최소 값을 구하여라
# 동일하게 그룹바이 문제
df['neighbourhood_group']
0 Brooklyn
1 Manhattan
2 Manhattan
3 Brooklyn
4 Manhattan
...
48890 Brooklyn
48891 Brooklyn
48892 Manhattan
48893 Manhattan
48894 Manhattan
Name: neighbourhood_group, Length: 48895, dtype: object
# 여러가지 연산에 필요한 함수를 한꺼번에 사용할때는 . agg 를 사용하여 문자열로 필요한 함수명을 입력한다.
df.groupby('neighbourhood_group')['price'].agg( ['mean', 'std' , 'max' , 'min' ] )

Pandas 실습 문제는 종료!
다음장에서는 Matplotlib과 Machine Learning 진행
Pandas 실습 문제 : value_counts() , to_frame(), groupby(), agg() 활용