# 기초개념에서 배운것들을 실습문제를 통해서 복습
import pandas as pd
DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/chipo.csv'
df = pd.read_csv(DataUrl)

ㄴ order_id 데이터를 보면 중복되는 데이터가 많은것을 볼수있다.
ㄴ 카테고리컬 데이터로 한사람이 여러가지의 메뉴를 한꺼번에 주문한것을 알수있다.
ㄴ 이럴때 중복없이 실제 주문을 한사람은 몇명인지 우선 파악해보는것도 중요하다.
# 실제주문건은?
df['order_id'].nunique()
1834ㄴ 총 4622개의 데이터중 중복값을 제외하면 1834개의 데이터가 유니크한 데이터임을 알수있다.
문제) quantity컬럼 값이 3인 데이터를 가져와서, index를 0부터 정렬하고 첫 5행을 출력하라
# .loc로 행 위치에 df['quantity'] == 3를 넣어 행값이 3인 모든 데이터를 , 열위치를 비어놔서 전체컬럼을 가져옴
df.loc[df['quantity'] == 3 , ]

# 리셋 인덱스
df.loc[df['quantity'] == 3 , ].reset_index()

# 상단 다섯개행 출력
df.loc[df['quantity'] == 3 , ].reset_index().head(5)
## 너무 코드가 기니 임의의 변수로 저장하여 한줄로 간단하게 만들수도 있다 ##
filter = df.loc[df['quantity'] == 3 , ]
filter.sort_index().head(5)
문제) quantity , item_price 두개의 컬럼으로 구성된 데이터 프레임을 가져오시오
# 3가지 방법으로 풀수 있다.
# 1) 컬럼기준으로 가져오는 것이므로 변수명 df 바로뒤에 [ ] 대가로는 컬럼명을 의미함. 직접 기재해서 인덱싱으로 가져오기.
# 2개 이상의 데이터이기 때문에 [ ] 데어태 액서스 가로 안에 [ ] 리스트로 불러와야함. [ ] 대가로의 속성이 서로 다른것임 꼭 주의해서 알아야함! (변수명 바로뒤에 [ ] 대가로는 데이터 억세스, [ [ ] ] 대가로 안에 대가로는 List를 뜻함)
df [ [ 'quantity','item_price' ] ]
# 2) loc를 활용 = loc는 인덱스 명, 컬럼 명 을 사용 (굵은 글씨)
df.loc[ : , ['quantity','item_price'] ]
# 3) iloc를 활용 = index의 위치를 숫자로 지정하여 사용
df.iloc[ : , [1,4] ]

ㄴ 3가지 코드 모두 동일한 결과값을 출력함
문제) item_price 컬럼의 달러표시 문자를 제거하고 float 타입으로 저장하여 new_price 컬럼에 저장하라
# item_price type이 문자열인걸 볼수있다.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4622 entries, 0 to 4621
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 order_id 4622 non-null int64
1 quantity 4622 non-null int64
2 item_name 4622 non-null object
3 choice_description 3376 non-null object
4 item_price 4622 non-null object
dtypes: int64(2), object(3)
memory usage: 180.7+ KB
# str.replace( '' , '' ) 문자열 내의 특정 부분 문자열을 다른 문자열로 대체
# 문자열을 실수형으로 변경 => .astype() 넘파이의 함수로 원하는 데이터 타입으로 변경 가능!!
df['item_price'].str.replace('$' , '').astype(float)
0 2.39
1 3.39
2 3.39
3 2.39
4 16.98
...
4617 11.75
4618 11.75
4619 11.25
4620 8.75
4621 8.75
Name: item_price, Length: 4622, dtype: float64
# new_price 를 원본 데이터에 새로운 컬럼으로 추가
df['new_price'] = df['item_price'].str.replace('$' , '').astype(float)
문제) new_price 컬럼이 5이하의 값을 가지는 데이터프레임을 추출하고, 데이터의 갯수는 몇개인가
# 바로 출력시켜서 하단 행령을 확인해도 되고,
df.loc [df['new_price'] <= 5 , ]
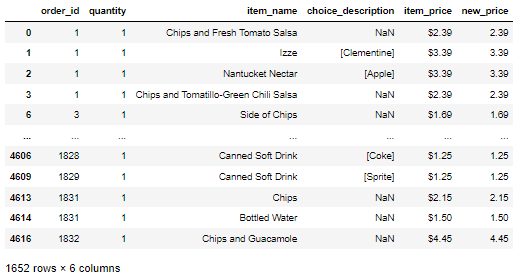
ㄴ 차트로 봤을때 하단 행갯수로 1652개인것 확인 가능
# sum 으로 봐도 됨
(df['new_price'] <= 5).sum()
1652
# shape 으로 행의 개수를 봐도됨
df.loc [df['new_price'] <= 5 , ].shape
(1652, 6)
## 번외 문제) quantity 가 1인 것중에 단열가격이 가장 비싼 항목을 찾아보자 ##
df.loc[df['quantity'] == 1 , ].sort_values('new_price' , ascending = False)
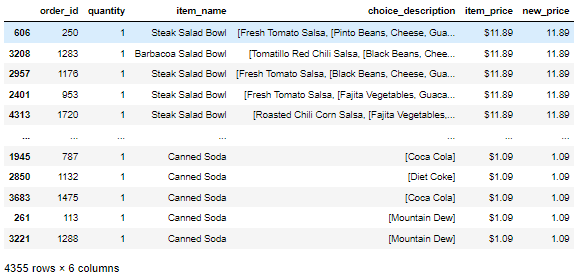
문제) new_price값이 9 이하이고 item_name 값이 Chicken Salad Bowl 인 데이터 프레임을 추출하라
# boolean indexing
df['new_price'] <= 9
0 True
1 True
2 True
3 True
4 False
...
4617 False
4618 False
4619 False
4620 True
4621 True
Name: new_price, Length: 4622, dtype: bool
df['item_name'] == 'Chicken Salad Bowl'
0 False
1 False
2 False
3 False
4 False
...
4617 False
4618 False
4619 True
4620 True
4621 True
Name: item_name, Length: 4622, dtype: bool
# 연산자(조건문 기호)를 사용하여 여러 조건을 한꺼번에 적용
(df['new_price'] <= 9) & (df['item_name'] == 'Chicken Salad Bowl')
0 False
1 False
2 False
3 False
4 False
...
4617 False
4618 False
4619 False
4620 True
4621 True
Length: 4622, dtype: bool
# 두 boolean Series를 & 연산자(조건문)로 결합하여 둘 다 True인 행만 선택하여 가져옴
df.loc[ (df['new_price'] <= 9) & (df['item_name'] == 'Chicken Salad Bowl') , ]

문제) df의 new_price 컬럼 값에 따라 오름차순으로 정리하고 index를 초기화 하여라
df.sort_values('new_price').reset_index()
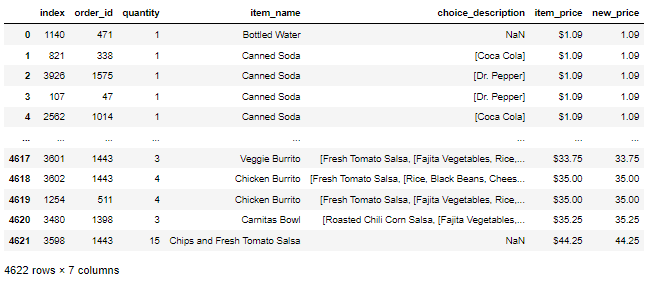
문제) df의 item_name 컬럼 값중 Chips 포함하는 경우의 데이터를 출력하라
df['item_name'].str.contains('Chips', case=False)
0 True
1 False
2 False
3 True
4 False
...
4617 False
4618 False
4619 False
4620 False
4621 False
Name: item_name, Length: 4622, dtype: bool
# boolen 인덱싱하여 데이터가 있는지 확인 하였으니 해당 데이터를 가져온다.
df.loc[ df['item_name'].str.contains('Chips', case=False) , ]

문제) df의 new_price 컬럼 값에 따라 내림차순으로 정리하고 index를 초기화 하여라
# sort_values() => 파라미터 안에 변수명을 입력하는것!
df.sort_values('new_price', ascending=False).reset_index()

문제) df의 item_name 컬럼 값이 Steak Salad 또는 Bowl 인 데이터를 가져오시오
# 포함된 문자열이 아니라 명확하게 단어가 정해진거면 str.contain보다 == 을 사용하여야 한다.
# == 사용 전에 str.lower()를 먼저 사용하여 소문자로 바꾸고 찾는 문자열을 == 소문자로 할경우 대/소문자 구분없이 모든 문자열을 찾는다.
# 코드가 너무 길어지므로 my_filter로 지정. | (or) 조건 기호를 사용하여 필요한 두가지 데이터를 모두 가져옴
my_filter = (df['item_name'].str.lower() == 'steak salad') | (df['item_name'].str.lower() == 'bowl')
my_filter
0 False
1 False
2 False
3 False
4 False
...
4617 False
4618 False
4619 False
4620 False
4621 False
Name: item_name, Length: 4622, dtype: bool
# 확인한 데이터를 가져옴
df.loc[ my_filter , ]

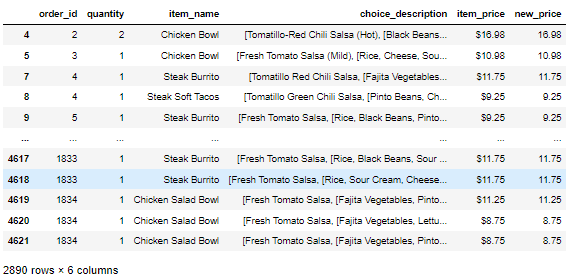
문제) df의 데이터 중 new_price값이 new_price값의 평균값 이상을 가지는 데이터들을 가져오시오
df['new_price'].mean()
7.464335785374297
# 평균값 이상인 데이터 찾기
df['new_price'] >= df['new_price'].mean()
0 False
1 False
2 False
3 False
4 True
...
4617 True
4618 True
4619 True
4620 True
4621 True
Name: new_price, Length: 4622, dtype: bool
# 찾아낸 데이터를 가져오기
df.loc[ df['new_price'] >= df['new_price'].mean() , ]
문제) df의 데이터 중 item_name의 값이 Izze 데이터를 Fizzy Lizzy로 수정하라
# df의 item_name 컬럼 중에 Izze 인 데이터를 우선 모두 찾아내라
df['item_name'].str.lower() == 'izze'
0 False
1 True
2 False
3 False
4 False
...
4617 False
4618 False
4619 False
4620 False
4621 False
Name: item_name, Length: 4622, dtype: bool
# 찾아낸 데이터중에 True인 행데이터에서 'item_name' 열 데이터만 골라서 가져와라
df.loc[ df['item_name'].str.lower() == 'izze' , 'item_name' ]
1 Izze
24 Izze
47 Izze
66 Izze
359 Izze
360 Izze
430 Izze
579 Izze
580 Izze
1059 Izze
1213 Izze
1611 Izze
1612 Izze
1680 Izze
2088 Izze
2619 Izze
2634 Izze
2758 Izze
2891 Izze
3669 Izze
Name: item_name, dtype: object
# 그지정한 값을 변경하여 저장한다! = 우측에 저장할 데이터 입력
df.loc[ df['item_name'].str.lower() == 'izze' , 'item_name' ] = 'Fizzy Lizzy'

ㄴ 원본 데이터에 변경되어 적용된것 확인
문제) df의 데이터 중 choice_description 값이 NaN 인 데이터의 갯수를 구하여라
# (1) 전체를 불러서 원하는 데이터만 확인하거나
df.isna().sum()
order_id 0
quantity 0
item_name 0
choice_description 1246
item_price 0
new_price 0
dtype: int64
# (2) 원하는 컬러만 불러내서 확인
df['choice_description'].isna().sum()
1246
문제) df의 데이터 중 choice_description 값이 NaN 인 데이터를 NoData 값으로 대체하라
# 채우는 것은 fillna()
df['choice_description'] = df['choice_description'].fillna('NoData')
df['choice_description']
0 NoData
1 [Clementine]
2 [Apple]
3 NoData
4 [Tomatillo-Red Chili Salsa (Hot), [Black Beans...
...
4617 [Fresh Tomato Salsa, [Rice, Black Beans, Sour ...
4618 [Fresh Tomato Salsa, [Rice, Sour Cream, Cheese...
4619 [Fresh Tomato Salsa, [Fajita Vegetables, Pinto...
4620 [Fresh Tomato Salsa, [Fajita Vegetables, Lettu...
4621 [Fresh Tomato Salsa, [Fajita Vegetables, Pinto...
Name: choice_description, Length: 4622, dtype: object
문제) df의 데이터 중 choice_description 값에 Black이 들어가는 경우를 가져오시오

# 특정 원하는 문자열 이므로 str.contains 사용
df['choice_description'].str.contains('Black', case=False)
0 False
1 False
2 False
3 False
4 True
...
4617 True
4618 False
4619 False
4620 False
4621 False
Name: choice_description, Length: 4622, dtype: bool
# 찾아낸 데이터를 가져오자.
df.loc[df['choice_description'].str.contains('Black', case=False), ]

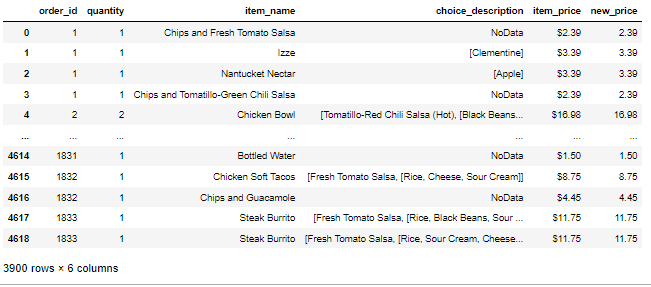
문제) df의 데이터 중 choice_description 값에 Vegetables 들어가지 않는 경우의 갯수를 출력하라
# 특정 문자열을 찾아낸후, case=False로 입력하면 해당 문자열이 없는데이터를 찾아오 그 데이터가 == False로 조건 기호를 입력하면 포함되지 않는 데이터를 가져오는것
df[df['choice_description'].str.contains('Vegetables', case=False) == False]
# 간단히 ~ 기호를 사용하여도됨 (파이썬 버전에 따라 지원되지 않을수도 있어서 확인 필요)
# True가 아닌 False인 데이터를 가져와서 해당 데이터를 불러와달라 ~ 를 사용
~(df['choice_description'].str.contains('Vegetables', case=False))
0 True
1 True
2 True
3 True
4 True
...
4617 True
4618 True
4619 False
4620 False
4621 False
Name: choice_description, Length: 4622, dtype: bool
# 갯수 확인
(~(df['choice_description'].str.contains('Vegetables', case=False))).sum()
3900
문제) df의 데이터 중 item_name 값이 N으로 시작하는 데이터를 모두 추출하라
# 시작하는 문자열을 찾는 함수는 str.startswith()
# , na=False 는 혹시 해당 문자열중에 NaN 값이 있을경우 해당 문자열은 False로 지정하는것
# N으로 시작하는 데이터를 가져오다보니 지정하지 않을경우 NaN까지 가져오기 때문에
# 원하는 데이터 확인
df['item_name'].str.lower().str.startswith('n' , na=False)
0 False
1 False
2 True
3 False
4 False
...
4617 False
4618 False
4619 False
4620 False
4621 False
Name: item_name, Length: 4622, dtype: bool
# 해당 데이터의 행,열 가져오기
df.loc[ df['item_name'].str.lower().str.startswith('n' , na=False) , ]

문제) df의 데이터 중 item_name 값의 글자개수가 15개 이상인 데이터를 가져오시오.
# 글자의 개수와 단어의 개수는 다르다.
# 글자 개수는 str.len() 함수로
df['item_name'].str.len() >= 15
0 True
1 False
2 True
3 True
4 False
...
4617 False
4618 False
4619 True
4620 True
4621 True
Name: item_name, Length: 4622, dtype: bool
df.loc [df['item_name'].str.len() >= 15, ]
## 번외 문제) 단어의 개수일 경우 => 공백을 기준으로 나눈다. split() ##
df['item_name'].str.split()
0 [Chips, and, Fresh, Tomato, Salsa]
1 [Izze]
2 [Nantucket, Nectar]
3 [Chips, and, Tomatillo-Green, Chili, Salsa]
4 [Chicken, Bowl]
...
4617 [Steak, Burrito]
4618 [Steak, Burrito]
4619 [Chicken, Salad, Bowl]
4620 [Chicken, Salad, Bowl]
4621 [Chicken, Salad, Bowl]
Name: item_name, Length: 4622, dtype: object
문제) df의 데이터 중 new_price값이 lst에 해당하는 경우의 데이터 프레임을 구하고 그 갯수를 출력하라
lst =[1.69, 2.39, 3.39, 4.45, 9.25, 10.98, 11.75, 16.98]
# .isin() 이라는 함수를 사용한다. => 가지고온 컬럼의 값이 lst 안에 들어있니??
# True인 데이터가 있는지 확인.
df['new_price'].isin(lst)
0 True
1 True
2 True
3 True
4 True
...
4617 True
4618 True
4619 False
4620 False
4621 False
Name: new_price, Length: 4622, dtype: bool
# 찾은 데이터를 가져옴
df.loc[ df['new_price'].isin(lst) , ]