
# 기초개념에서 배운것들을 실습문제를 통해서 복습
winemag-data-130k-v2.csv 파일을 reviews 로 읽는다.
# import
import pandas as pd
pd.read_csv('../data/winemag-data.csv')
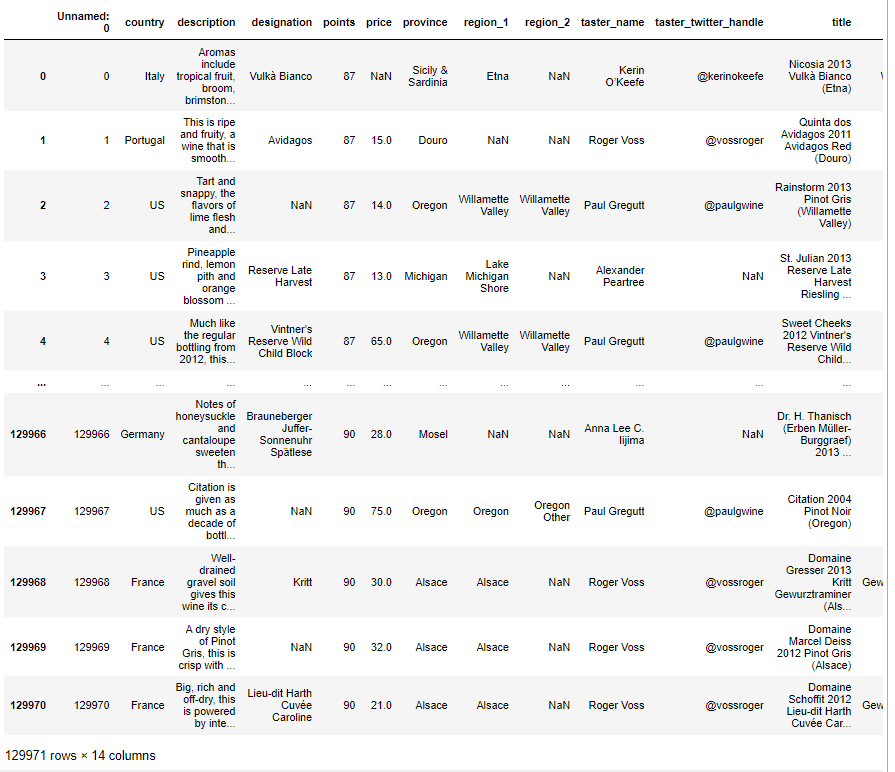
ㄴ Unnamed: 0 라고 뜨는것은 인덱스가 컬럼으로 올라온것이라 밑으로 네려줘야함
# index_col= 0 자리에 'Unnamed: 0' 로 적어줘도됨
pd.read_csv('../data/winemag-data.csv' , index_col= 0)
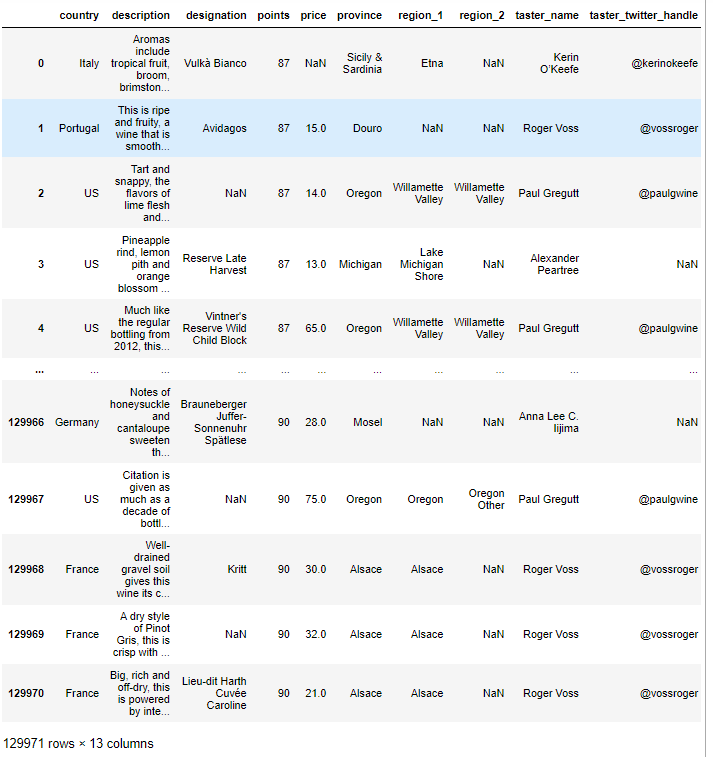
# 변수로 저장
df = pd.read_csv('../data/winemag-data.csv' , index_col= 0)
문제) 인덱스를 title 컬럼으로 셋팅한다.
# 변수명.set_index('셋팅할 컬럼명', 저장 여부) 사용
df.set_index('title', inplace=True)
ㄴ inplace=True는 변수에 바로 저장한다는 파라미터 명령어
문제) 먼저 데이터가 비어있느것이 있는지 확인한다.
df.isna()
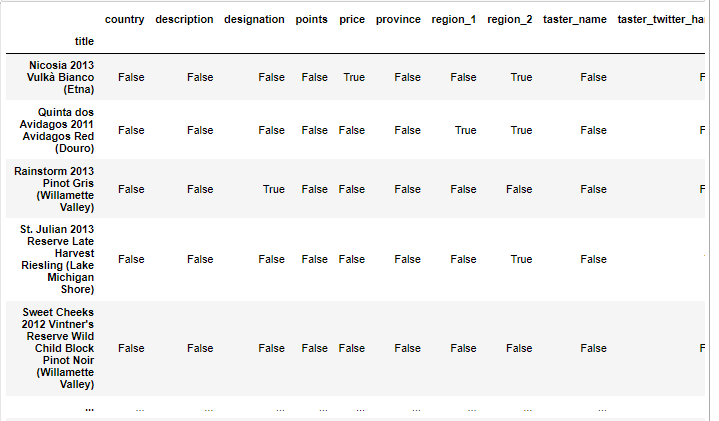
ㄴ True인 데이터가 있으므로 비어있다는걸 알수 있음.
# 컬럼 별로 비어있는 개수를 보고싶으면?
df.isna().sum()
country 63
description 0
designation 37465
points 0
price 8996
province 63
region_1 21247
region_2 79460
taster_name 26244
taster_twitter_handle 31213
variety 1
winery 0
critic 0
dtype: int64
문제) 그리고나서, 가격이 없는 데이터는 빼고, 데이터셋을 가져온다.
# 가격 컬럼에서 .notna() 빈칸이 있는 행을 제외하고 불러옴
df['price'].notna()
title
Nicosia 2013 Vulkà Bianco (Etna) False
Quinta dos Avidagos 2011 Avidagos Red (Douro) True
Rainstorm 2013 Pinot Gris (Willamette Valley) True
St. Julian 2013 Reserve Late Harvest Riesling (Lake Michigan Shore) True
Sweet Cheeks 2012 Vintner's Reserve Wild Child Block Pinot Noir (Willamette Valley) True
...
Dr. H. Thanisch (Erben Müller-Burggraef) 2013 Brauneberger Juffer-Sonnenuhr Spätlese Riesling (Mosel) True
Citation 2004 Pinot Noir (Oregon) True
Domaine Gresser 2013 Kritt Gewurztraminer (Alsace) True
Domaine Marcel Deiss 2012 Pinot Gris (Alsace) True
Domaine Schoffit 2012 Lieu-dit Harth Cuvée Caroline Gewurztraminer (Alsace) True
Name: price, Length: 129971, dtype: bool
# loc 를 사용하여 해당 데이터를 가져와 df_price 변수로 따로 저장
df_price = df.loc[df['price'].notna() , ]
# 진짜 비어있지 않은지 확인
df_price.isna().sum()
country 59
description 0
designation 34779
points 0
price 0
province 59
region_1 19575
region_2 70683
taster_name 24496
taster_twitter_handle 29416
variety 1
winery 0
critic 0
dtype: int64ㄴ price 컬럼은 0인것을 보아 비어있는 데이터가 없는것을 확인할수 있다.
문제) 리뷰에 새로운 컬럼 critic 만들고, everyone 이라고 값 넣는다.
# 반복문 사용해서 리스트 지정해서 넣어줄 필요없이, pandas를 이용하면 문자열만 적어줘도 된다.
# df['생성할 컬럼명'] = '그안에 넣어줄 데이터'
df['critic'] = 'everyone'
문제) 리뷰의 포인트 컬럼은 수치로 되어있다. 이 컬럼의 기초통계데이터를 확인하시오. (평균, 최대 최소 등)
# points가 진짜 수치인가 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
Index: 129971 entries, Nicosia 2013 Vulkà Bianco (Etna) to Domaine Schoffit 2012 Lieu-dit Harth Cuvée Caroline Gewurztraminer (Alsace)
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 129908 non-null object
1 description 129971 non-null object
2 designation 92506 non-null object
3 points 129971 non-null int64
4 price 120975 non-null float64
5 province 129908 non-null object
6 region_1 108724 non-null object
7 region_2 50511 non-null object
8 taster_name 103727 non-null object
9 taster_twitter_handle 98758 non-null object
10 variety 129970 non-null object
11 winery 129971 non-null object
12 critic 129971 non-null object
dtypes: float64(1), int64(1), object(11)
memory usage: 17.9+ MBㄴ Dtype이 int인것 확인
# 평균
df['points'].mean()
88.44713820775404
# 최대값
df['points'].max()
100
# 최소값
df['points'].min()
80
# .describe() 로 한번에 처리해서 볼수도 있다.
df['points'].describe()
count 129971.000000
mean 88.447138
std 3.039730
min 80.000000
25% 86.000000
50% 88.000000
75% 91.000000
max 100.000000
Name: points, dtype: float64
문제) taster_name 컬럼은 사람 이름으로 되어있다. 몇명의 사람들이 평가를 한것인까?
# 전체 행(데이터)은 몇개인가? => 129971
df.shape
(129971, 13)
# 유니크한 항목은 뭐뭐가 있나?
df['taster_name'].unique()
array(['Kerin O’Keefe', 'Roger Voss', 'Paul Gregutt',
'Alexander Peartree', 'Michael Schachner', 'Anna Lee C. Iijima',
'Virginie Boone', 'Matt Kettmann', nan, 'Sean P. Sullivan',
'Jim Gordon', 'Joe Czerwinski', 'Anne Krebiehl\xa0MW',
'Lauren Buzzeo', 'Mike DeSimone', 'Jeff Jenssen',
'Susan Kostrzewa', 'Carrie Dykes', 'Fiona Adams',
'Christina Pickard'], dtype=object)ㄴ 일일이 새보면 20명인것을 알수 있다.
# 자동으로 유니크한 항목의 갯수 확인 nunique()
df['taster_name'].nunique()
19ㄴ 총 19명의 테스터가 평가한것 확인
## 해당 결과가 다른 이유는 unique() 함수는 빈칸인 nan 항목도 데이터로 치부하여 개수를 함께 카운트하기때문이다.
## nunique()는 default로 dropna=True 속성을 가지고 있어서 nan 항목을 제외하고 보여준다.
## 만약 unique() 함수로 nan을 제외하고 보고싶다면 미리 사전에 dropna이나 fillna로 데이터를 지우거나 채우고 실행하면 된다.
## 반대로 nunique()로 nan을 포함하여 보고 싶다면 nunique() 파라미터 안에 dropna=False를 넣으면 nan을 포함하여 카운트 한다. (but, 해당 방법은 nunique에서만 사용가능하고 unique함수 파라미터 안에는 dropna= 를 직접적으로 받지를 못해서 번거롭지만 먼저 dropna로 데이터에서 뺀후 실행하여야 한다.)
문제) 테스터들의 이름을 전부 확인하시오
# 상단에서 설명한것처럼 dropna를 먼저 사용하여 제외하고 unique 실행
df['taster_name'].dropna().unique()
array(['Kerin O’Keefe', 'Roger Voss', 'Paul Gregutt',
'Alexander Peartree', 'Michael Schachner', 'Anna Lee C. Iijima',
'Virginie Boone', 'Matt Kettmann', 'Sean P. Sullivan',
'Jim Gordon', 'Joe Czerwinski', 'Anne Krebiehl\xa0MW',
'Lauren Buzzeo', 'Mike DeSimone', 'Jeff Jenssen',
'Susan Kostrzewa', 'Carrie Dykes', 'Fiona Adams',
'Christina Pickard'], dtype=object)ㄴ 세어보면 19명인것을 알수 있다.
# size를 활용해서 갯수를 비교해 보자
df['taster_name'].dropna().unique().size
19
df['taster_name'].unique().size
20
### 그러므로 카테고리컬 데이터의 명칭을 확인할때는 비어있는 데이터가 없는지 꼭 확인작업이 필요!!
문제) 각 테스터들은, 각각 몇개의 와인을 테스트 했는지 확인하시오. ( 테스터 이름, 갯수 )
# (1) .groupby를 활용하여 확인 가능
# 각테스터 네임별로 같은 테스터 네임 컬럼을 참고해서 데이터가 몇개씩인지 보면 데이터 갯수를 확인할수 있음
df.groupby('taster_name')['taster_name'].count()
taster_name
Alexander Peartree 415
Anna Lee C. Iijima 4415
Anne Krebiehl MW 3685
Carrie Dykes 139
Christina Pickard 6
Fiona Adams 27
Jeff Jenssen 491
Jim Gordon 4177
Joe Czerwinski 5147
Kerin O’Keefe 10776
Lauren Buzzeo 1835
Matt Kettmann 6332
Michael Schachner 15134
Mike DeSimone 514
Paul Gregutt 9532
Roger Voss 25514
Sean P. Sullivan 4966
Susan Kostrzewa 1085
Virginie Boone 9537
Name: taster_name, dtype: int64
# (2) .value_counts() 활용
df['taster_name'].value_counts()
taster_name
Roger Voss 25514
Michael Schachner 15134
Kerin O’Keefe 10776
Virginie Boone 9537
Paul Gregutt 9532
Matt Kettmann 6332
Joe Czerwinski 5147
Sean P. Sullivan 4966
Anna Lee C. Iijima 4415
Jim Gordon 4177
Anne Krebiehl MW 3685
Lauren Buzzeo 1835
Susan Kostrzewa 1085
Mike DeSimone 514
Jeff Jenssen 491
Alexander Peartree 415
Carrie Dykes 139
Fiona Adams 27
Christina Pickard 6
Name: count, dtype: int64ㄴ .groupby의 경우 어떤 컬럼을 참고하여 다른 컬럼의 데이터를 보고싶을때 유용하고, 한개의 컬럼만 가지고 비교하면 될경우에는 value_counts()가 가장 효율적
문제) 리뷰의 포인트의 평균을 구하고, 리뷰의 포인트값이, 평균보다 큰 데이터 (즉, 평가가 좋은 와인) 만 가져오시오.
# 평균을 구하여
df['points'].mean()
88.44713820775404
# 평균보다 높은 데이터를 호출
df['points'] > df['points'].mean()
title
Nicosia 2013 Vulkà Bianco (Etna) False
Quinta dos Avidagos 2011 Avidagos Red (Douro) False
Rainstorm 2013 Pinot Gris (Willamette Valley) False
St. Julian 2013 Reserve Late Harvest Riesling (Lake Michigan Shore) False
Sweet Cheeks 2012 Vintner's Reserve Wild Child Block Pinot Noir (Willamette Valley) False
...
Dr. H. Thanisch (Erben Müller-Burggraef) 2013 Brauneberger Juffer-Sonnenuhr Spätlese Riesling (Mosel) True
Citation 2004 Pinot Noir (Oregon) True
Domaine Gresser 2013 Kritt Gewurztraminer (Alsace) True
Domaine Marcel Deiss 2012 Pinot Gris (Alsace) True
Domaine Schoffit 2012 Lieu-dit Harth Cuvée Caroline Gewurztraminer (Alsace) True
Name: points, Length: 129971, dtype: bool
# 해당 데이터를 행렬로 가져온다.
df.loc[ df['points'] > df['points'].mean() , ]
