
# 기초개념에서 배운것들을 실습문제를 통해서 복습
import pandas as pd
# 리뷰 데이터를 read해 df 변수로 메모리에 업로드
df = pd.read_csv('../data/winemag-data.csv' , index_col=0)
문제) 리뷰 데이터프레임에서 points 컬럼의 median 값은?
df['points'].median()
88.0
# describe()를 통해 한꺼번에 볼수도 있음. median()은 정렬후 정가운데 값이므로 50% 값과 일치
df['points'].describe()
count 129971.000000
mean 88.447138
std 3.039730
min 80.000000
25% 86.000000
50% 88.000000
75% 91.000000
max 100.000000
Name: points, dtype: float64
문제) 나라를 중복되지 않도록 가져와서 countries 변수에 저장하고, 화면에 출력하시오.
df['country'].unique()
array(['Italy', 'Portugal', 'US', 'Spain', 'France', 'Germany',
'Argentina', 'Chile', 'Australia', 'Austria', 'South Africa',
'New Zealand', 'Israel', 'Hungary', 'Greece', 'Romania', 'Mexico',
'Canada', nan, 'Turkey', 'Czech Republic', 'Slovenia',
'Luxembourg', 'Croatia', 'Georgia', 'Uruguay', 'England',
'Lebanon', 'Serbia', 'Brazil', 'Moldova', 'Morocco', 'Peru',
'India', 'Bulgaria', 'Cyprus', 'Armenia', 'Switzerland',
'Bosnia and Herzegovina', 'Ukraine', 'Slovakia', 'Macedonia',
'China', 'Egypt'], dtype=object)ㄴ 해당 문제에선 이후 NaN이 크게 문제되지 않아 그냥 포함하였지만 실제 데이터 처리에서는 NaN을 제외하도록 dropna()를 실행한후 unique() 를 사용하는것이 좋다.
countries = df['country'].unique()
# 변수로 저장한후 확인
print(countries)
['Italy' 'Portugal' 'US' 'Spain' 'France' 'Germany' 'Argentina' 'Chile'
'Australia' 'Austria' 'South Africa' 'New Zealand' 'Israel' 'Hungary'
'Greece' 'Romania' 'Mexico' 'Canada' nan 'Turkey' 'Czech Republic'
'Slovenia' 'Luxembourg' 'Croatia' 'Georgia' 'Uruguay' 'England' 'Lebanon'
'Serbia' 'Brazil' 'Moldova' 'Morocco' 'Peru' 'India' 'Bulgaria' 'Cyprus'
'Armenia' 'Switzerland' 'Bosnia and Herzegovina' 'Ukraine' 'Slovakia'
'Macedonia' 'China' 'Egypt']
문제) 각 국가별로는 몇개의 리뷰가 있는지, 각국가별 리뷰수를 구하시오.
# 두가지 방법이 있다. groupby와 value_counts()를 사용하는것
# 1) 같은 컬럼을 참고해서 그 갯수만 확인하면 되므로 .groupby를 같은 컬럼으로 사용
df.groupby('country')['country'].count()
country
Argentina 3800
Armenia 2
Australia 2329
Austria 3345
Bosnia and Herzegovina 2
Brazil 52
Bulgaria 141
Canada 257
Chile 4472
China 1
Croatia 73
Cyprus 11
Czech Republic 12
Egypt 1
England 74
France 22093
Georgia 86
Germany 2165
Greece 466
Hungary 146
India 9
Israel 505
Italy 19540
Lebanon 35
Luxembourg 6
Macedonia 12
Mexico 70
Moldova 59
Morocco 28
New Zealand 1419
Peru 16
Portugal 5691
Romania 120
Serbia 12
Slovakia 1
Slovenia 87
South Africa 1401
Spain 6645
Switzerland 7
Turkey 90
US 54504
Ukraine 14
Uruguay 109
Name: country, dtype: int64
# groupby 값을 정렬할수도 있다
df.groupby('country')['country'].count().sort_values()
ㄴ values로 할경우 값을 기준으로 내림차순 하고 싶으면 () 안에 ascending = False 사용 빈칸일경우 자동 오름차순
country
China 1
Slovakia 1
Egypt 1
Armenia 2
Bosnia and Herzegovina 2
Luxembourg 6
Switzerland 7
India 9
Cyprus 11
Czech Republic 12
Serbia 12
Macedonia 12
Ukraine 14
Peru 16
Morocco 28
Lebanon 35
Brazil 52
Moldova 59
Mexico 70
Croatia 73
England 74
Georgia 86
Slovenia 87
Turkey 90
Uruguay 109
Romania 120
Bulgaria 141
Hungary 146
Canada 257
Greece 466
Israel 505
South Africa 1401
New Zealand 1419
Germany 2165
Australia 2329
Austria 3345
Argentina 3800
Chile 4472
Portugal 5691
Spain 6645
Italy 19540
France 22093
US 54504
Name: country, dtype: int64
# 인덱스로 정렬할경우
df.groupby('country')['country'].count().sort_index()
country
Argentina 3800
Armenia 2
Australia 2329
Austria 3345
Bosnia and Herzegovina 2
Brazil 52
Bulgaria 141
Canada 257
Chile 4472
China 1
Croatia 73
Cyprus 11
Czech Republic 12
Egypt 1
England 74
France 22093
Georgia 86
Germany 2165
Greece 466
Hungary 146
India 9
Israel 505
Italy 19540
Lebanon 35
Luxembourg 6
Macedonia 12
Mexico 70
Moldova 59
Morocco 28
New Zealand 1419
Peru 16
Portugal 5691
Romania 120
Serbia 12
Slovakia 1
Slovenia 87
South Africa 1401
Spain 6645
Switzerland 7
Turkey 90
US 54504
Ukraine 14
Uruguay 109
Name: country, dtype: int64
# 2) 정렬해서 보여주기 때문에 .value_counts() 가 좀더 효율적
# .value_counts() 자동으로 내림차순 정렬이기 때문에 오름차순으로 보고싶다면 sort_values()를 추가로 붙이면됨
# 내림차순
df['country'].value_counts()
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
Chile 4472
Argentina 3800
Austria 3345
Australia 2329
Germany 2165
New Zealand 1419
South Africa 1401
Israel 505
Greece 466
Canada 257
Hungary 146
Bulgaria 141
Romania 120
Uruguay 109
Turkey 90
Slovenia 87
Georgia 86
England 74
Croatia 73
Mexico 70
Moldova 59
Brazil 52
Lebanon 35
Morocco 28
Peru 16
Ukraine 14
Serbia 12
Czech Republic 12
Macedonia 12
Cyprus 11
India 9
Switzerland 7
Luxembourg 6
Bosnia and Herzegovina 2
Armenia 2
Slovakia 1
China 1
Egypt 1
Name: count, dtype: int64
# 오름차순
df['country'].value_counts().sort_values()
country
Egypt 1
China 1
Slovakia 1
Armenia 2
Bosnia and Herzegovina 2
Luxembourg 6
Switzerland 7
India 9
Cyprus 11
Serbia 12
Macedonia 12
Czech Republic 12
Ukraine 14
Peru 16
Morocco 28
Lebanon 35
Brazil 52
Moldova 59
Mexico 70
Croatia 73
England 74
Georgia 86
Slovenia 87
Turkey 90
Uruguay 109
Romania 120
Bulgaria 141
Hungary 146
Canada 257
Greece 466
Israel 505
South Africa 1401
New Zealand 1419
Germany 2165
Australia 2329
Austria 3345
Argentina 3800
Chile 4472
Portugal 5691
Spain 6645
Italy 19540
France 22093
US 54504
Name: count, dtype: int64
문제) 리뷰 데이터프레임의 price 컬럼 값에서, price의 평균값을 뺀 값을, centered_price 라고 저장하시오.
# price 컬럼의 평균을 우선 구한 후, 해당 컬럼값에서 평균값을 뺀후 변수로 저장한다.
# price의 평균값
df['price'].mean()
35.363389129985535
centered_price = df['price'] - df['price'].mean()
# 저장된 데이터 확인
centered_price
0 NaN
1 -20.363389
2 -21.363389
3 -22.363389
4 29.636611
...
129966 -7.363389
129967 39.636611
129968 -5.363389
129969 -3.363389
129970 -14.363389
Name: price, Length: 129971, dtype: float64
문제) 나는 경제적이므로, 가격대비 포인트가 가장 큰 와인을 사려한다. 해당 와인의 title은?
# 데이터 : 숫자(정수,실수) , 문자열
# 데이터 가공 : 숫자는 연산, 문자열은 처리
# 가성비가 가장 좋은 값은 포인트 대비 가격이므로 point 나누기 price 값이 가장 높은것을 말한다.
# but 해당 리뷰에는 가성비를 판단할수 있는 기준이될 컬럼(그컬럼에 속한 데이터까지)이 존재하지 않는다.
# 그러므로 point 나누기 price 값으로 새로운 컬럼을 생성하여 원본데이터에 넣어준후 그 컬럼을 기준으로 찾을수 있다.
# 여기선 임의로 'top' 란 이름으로 컬럼 생성
df['top'] = df['points'] / df['price']
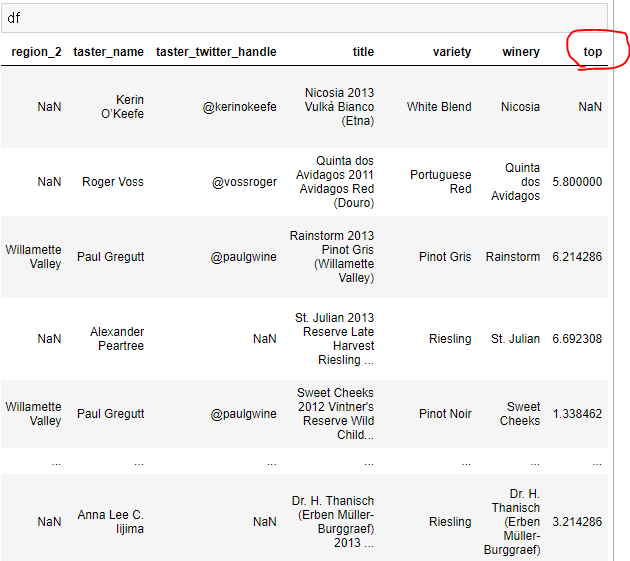
ㄴ 원본 데이터의 'top' 컬럼 생성 확인
# (1) 이제 해당 컬럼을 가지고 가성비('top')가 가장 높은 항목 두개의 행을 찾는다.
df['top'] == df['top'].max()
0 False
1 False
2 False
3 False
4 False
...
129966 False
129967 False
129968 False
129969 False
129970 False
Name: top, Length: 129971, dtype: bool
# 블린형식으로 출력된 행을 보여줘라
df.loc[df['top'] == df['top'].max() , ]
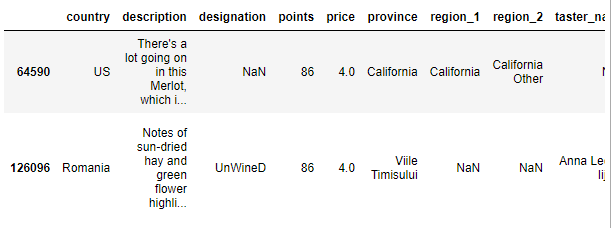
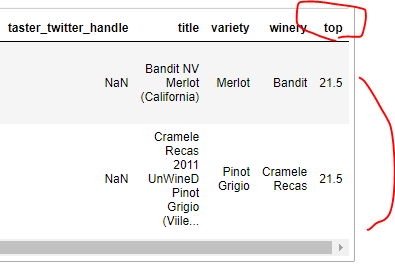
ㄴ 'top' 컬럼값이 가장 높은 두개의 데이터(행)이 출력된것 확인
# (2) 가성비('top')를 정렬하여 가장 큰 값을 찾는다.
df.sort_values('top' , ascending=False)
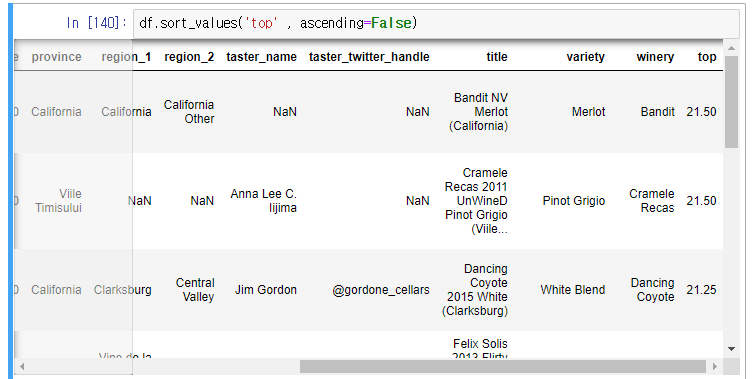
ㄴ 내림차순으로 정렬되어 출력되는것 확인
# 상단리스트만 보고싶다
df.sort_values('top' , ascending=False).head(5)

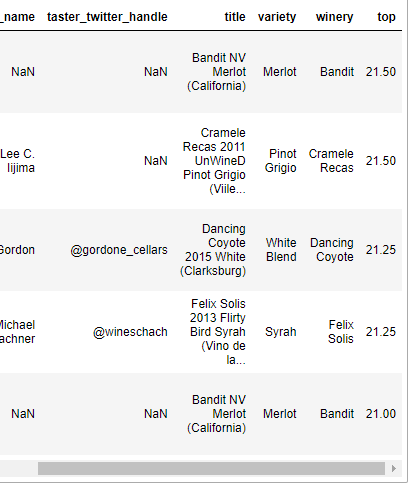
ㄴ 상위 5개 데이터만 출력
# 타이틀만 보고싶다
df.sort_values('top' , ascending=False).head(5)['title']
64590 Bandit NV Merlot (California)
126096 Cramele Recas 2011 UnWineD Pinot Grigio (Viile...
20484 Dancing Coyote 2015 White (Clarksburg)
1987 Felix Solis 2013 Flirty Bird Syrah (Vino de la...
110255 Bandit NV Merlot (California)
Name: title, dtype: object
# ... 으로 줄여져 있는걸 보고싶다. 해당 형태는 판다스 시리즈이므로 인덱스로 불러온다
df.sort_values('top' , ascending=False).head(5)['title'][126096]
'Cramele Recas 2011 UnWineD Pinot Grigio (Viile Timisului)'
## 원하는 여러 가지 방식으로 사용자가 원하는 형태로 불러올수 있다 ##
문제)
사람들이 어떤와인을 더 많이 거론했는지 보려한다.
"tropical" 이 들어있는 리뷰의 갯수는 몇개입니까?
"fruity" 라고 들어있는 리뷰의 갯수를 세어서
판다스 시리즈로 descriptor_counts 변수로 만들어 보자.
# "tropical", "fruity" 단어는 'description' 컬럼에 들어있다. 특정 원하는 단어를 포함한 데이터를 찾는등 문자열에만 적용할수 있는 문자열 함수가 따로 있다.
# https://pandas.pydata.org/docs/reference/api/pandas.Series.str.contains.html
ㄴ 필요에 따라 레퍼런스에서 필요한 함수를 찾아서 설명서에 맞게 적용할줄 알아야 한다.
# 검색을 하는것도 중요하다 단어를 찾는 함수는 str.contains() 규칙도 알아야 한다.
# 대소문자 구분하지 않기위해 case=False 를 입력해 준다. default는 True
df['description'].str.contains('tropical', case=False).sum()
3800ㄴ 'tropical' 이 포함된 데이터는 3800 개
df['description'].str.contains('fruity', case=False).sum()
9455ㄴ 'fruity' 포함된 데이터는 9455 개
# 두개의 총합이므로 더하여 새로운 변수로 저장 후 호출
descriptor_counts = (df['description'].str.contains('tropical', case=False).sum()) + (df['description'].str.contains('fruity', case=False).sum())
descriptor_counts
13255
문제)
별점 시스템을 만들려고 한다. 따라서 별점에 대한 데이터가 필요하다.
별점은 1,2,3 즉 3개로 만들것이다.
포인트가 95점 이상이면 3점, 85점 이상이면 2점, 나머지는 1점으로 할 것이다.
리뷰데이터를 통해 각 데이터의 별점을 구하시오.
# 조건에 맞는 새로운 함수 생성
def get_rating(points):
if points >= 95:
return 3
elif 95 >= points >= 85:
return 2
else :
return 1
# 잘동작되는지 확인
get_rating(96)
3
# 데이터프레임워크에 적용 해봐야 한다.
# .apply를 사용하여 새로 만든 함수인 get_group을 적용
df['points'].apply( get_group )
0 2
1 2
2 2
3 2
4 2
..
129966 2
129967 2
129968 2
129969 2
129970 2
Name: points, Length: 129971, dtype: int64ㄴ 잘 적용되는것 확인
# 해당 함수식으로 리턴받은 값을 원본에 'star' 라는 컬럼으로 집어 넣기
df['star'] = df['points'].apply( get_group )
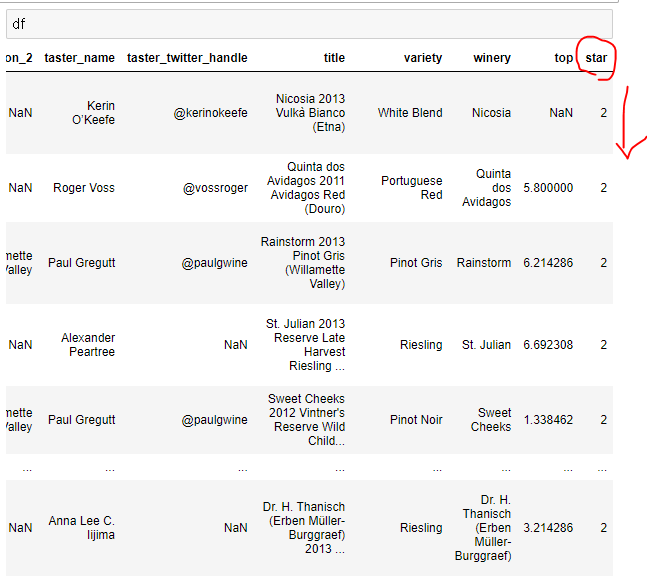
ㄴ 원본 데이터에 'star' 컬럼 생성 확인
문제) 리뷰의 region_2 컬럼에 데이터가 비어있는 경우에는, 'Unknown'으로 셋팅하자.
# isna : 비어있니? notna : 채워져 있니? fillna : 비어있는걸 채워줘 dropna : 비어있는걸 없애줘# 대체한 값이 원본 데이터에 바로 저장되도록 코드 작성df['region_2'] = df['region_2'].fillna('Unknown')
ㄴ 원본 데이터에 정상 적용된것 확인