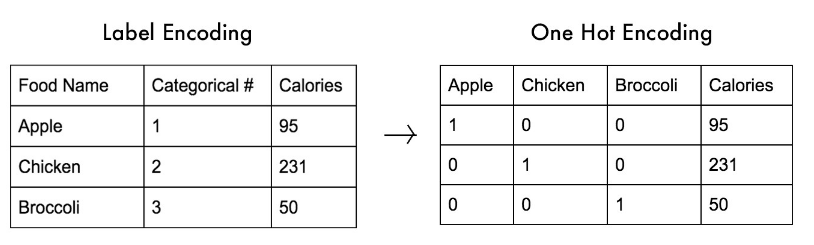
# 전장에서 사용하였던 데이터프레임을 가지고와 이어서 진행 Age 와 Salary 는 같은 스케일이 아니다. Age 는 27 ~ 50 Salary 는 40k ~ 90k (만단위) # 유클리디언 디스턴스로 오차를 줄여 나가는데, 하나의 변수는 오차가 크고, 하나의 변수는 오차가 작으면, 나중에 오차를 수정할때 편중되게 된다. # 따라서 값의 레인지를 맞춰줘야 정확히 트레이닝 된다. 표준화 : 평균을 기준으로 얼마나 떨어져 있느냐? 같은 기준으로 만드는 방법, 음수도 존재, 데이터의 최대최소값 모를때 사용. 정규화 : 0 ~ 1 사이로 맞추는 것. 데이터의 위치 비교가 가능, 데이터의 최대최소값 알떄..