< Linear Regression 이란 >
경력과 연봉의 관계(스케터를 이용)를 분석하여, 경력이 주어졌을때 연봉을 예측하려 한다.
데이터를 살펴보니, 아래와 같은 그래프로 나왔다고 가정했을 때,

아래 그림처럼, 해당 분포를 만족하는 직선을 찾으려(데이터의 피팅되는 방적식을 찾는것) 하는것이 목표이다.
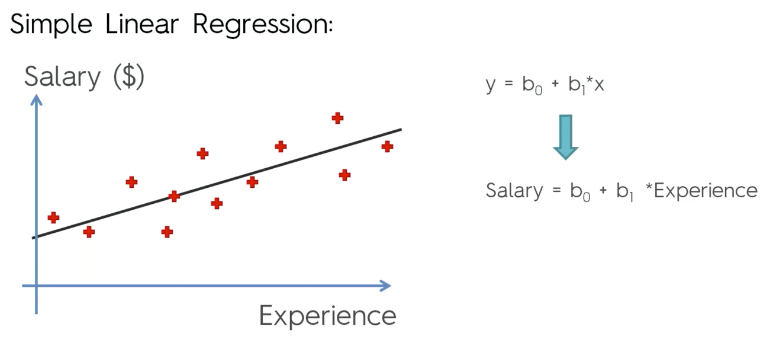
직선을 찾기 위해서는 우리가 잘 아는 직선의 방정식을 이용하여,
직선의 기울기와 y절편을 구하면 되는것이다.

여기에서 주의! x, y 가 우리에게 데이터셋으로 주어졌다. 따라서 우리는 b 를 찾아야 하는것이다.

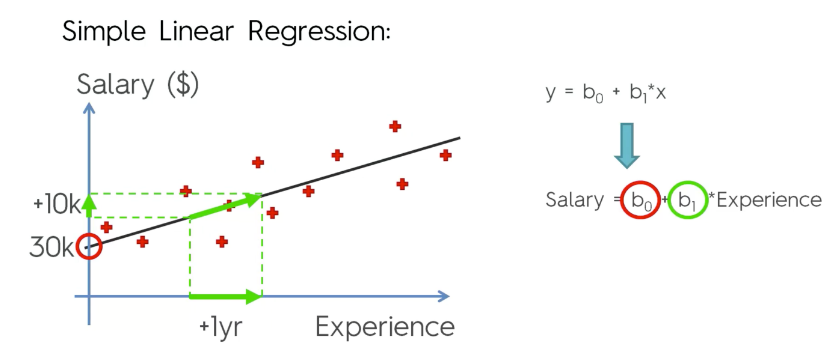
즉, b0, b1 의 값을 찾아 가는 과정을 학습이라고 부른다!
그렇다면 학습이란??? 바로 error(오차)를 줄여 나가는 것이다.
아래는 오차를 나타낸다.
그렇다면 오차(error)란? [오차 = 실제값 - 예측값 => 해당 규칙은 외워야함!]
그리고 직선은 처음에 어디서 가져오지?
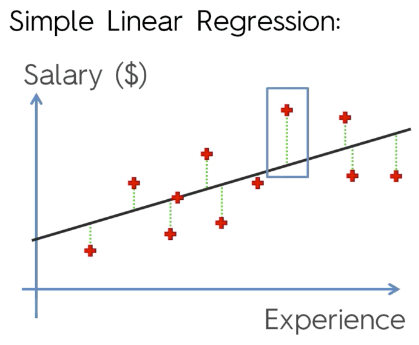
모든 관측점(Observation) 에서의 y값의 error(오차)가 존재하고, 이 오차들의 총 합을 줄여 나가면 된다.
제곱을 하는 이유는? => 부호가 있으므로 제곱하여 - 값을 없애기 위해서

오차를 줄여 나가서, 최소값이 되는 직선을 찾으면 끝난다.
최소값이 될때의 어떤 값을 찾는 것인가?

< 예제를 통하여 실제로 적용해가면서 정리 해보자 >
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 불러오기
'Salary_Data.csv' 를 읽으세요.
경력과 연봉의 관계 분석을 통해, 누군가 입사했을 때,
그사람의 경력에 맞는 연봉을 제시해 줄 수 있도록 합니다.
df = pd.read_csv('../data/Salary_Data.csv')
df.shape
# 전체데이터 개수는 30개
(30, 2)
# 1) 비어있는 데이터가 있으면 안되므로 NaN 처리
df.isna().sum()
# 없으므로 깨끗한 데이터
YearsExperience 0
Salary 0
dtype: int64
# 2) X와 y로 분리
# 우리가 예측하려는건 연차에 따른 연봉이므로 Salary 가 y = df['Salary']
y
0 39343.0
1 46205.0
2 37731.0
3 43525.0
4 39891.0
5 56642.0
6 60150.0
7 54445.0
8 64445.0
9 57189.0
10 63218.0
11 55794.0
12 56957.0
13 57081.0
14 61111.0
15 67938.0
16 66029.0
17 83088.0
18 81363.0
19 93940.0
20 91738.0
21 98273.0
22 101302.0
23 113812.0
24 109431.0
25 105582.0
26 116969.0
27 112635.0
28 122391.0
29 121872.0
Name: Salary, dtype: float64
# 비교열이 되는 X 는 무조건 2차원이어야 하므로 to_frame()으로 2차원으로 만들어 줘야함
X = df['YearsExperience'].to_frame()
X

# 3) 문자열 데이터를 숫자로 바꾼다.
# 문자열 데이터가 없으므로 패스
# 4) 피쳐 스케일링
# 지금 배우는 리니어 리그레션은 자체적으로 피처 스케일링을 해주기 때문에 따로 해줄 필요가 없다.
# 딥러닝은 무조건 해주어야 한다. 추후 학습..
# 5) Training 과 Test 용으로 데이터를 분리
from sklearn.model_selection import train_test_split
train_test_split( X, y, test_size=0.2 , random_state= 11)
[ YearsExperience
14 4.5
21 7.1
9 3.7
5 2.9
10 3.9
22 7.9
2 1.5
4 2.2
20 6.8
29 10.5
19 6.0
0 1.1
28 10.3
24 8.7
18 5.9
7 3.2
1 1.3
12 4.0
13 4.1
23 8.2
17 5.3
27 9.6
16 5.1
25 9.0,
YearsExperience
15 4.9
8 3.2
6 3.0
26 9.5
3 2.0
11 4.0,
14 61111.0
21 98273.0
9 57189.0
5 56642.0
10 63218.0
22 101302.0
2 37731.0
4 39891.0
20 91738.0
29 121872.0
19 93940.0
0 39343.0
28 122391.0
24 109431.0
18 81363.0
7 54445.0
1 46205.0
12 56957.0
13 57081.0
23 113812.0
17 83088.0
27 112635.0
16 66029.0
25 105582.0
Name: Salary, dtype: float64,
15 67938.0
8 64445.0
6 60150.0
26 116969.0
3 43525.0
11 55794.0
Name: Salary, dtype: float64]
# 변수명 순서는 약속된 규칙이므로 절대 바꾸어선 안된다!
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2 , random_state= 11)
X_train.shape
(24, 1)
y_train.shape
(24,)
X_test.shape
(6, 1)
y_test.shape
(6,)
# 여기까지가 데이터 프리프로세싱
# 데이터 프리프로세싱(Data Preprocessing)은 머신러닝 모델을 학습시키기 전에 데이터를 정제하고 준비하는 과정
< 이제 모데링을 한다 >
### 연봉을 예측하려 한다! => 수치로 나오는 것 ! ex) 3726.16 94761.34
### => Regression (수치형 예측)
from sklearn.linear_model import LinearRegression
# 깡통 인공지능을 하나 분양 받음 (바보 상태) => 학습 시켜야 한다.
regressor = LinearRegression()
# 인공지능을 학습시킨다.
# 위에서 만든 X_train, X_test, y_train, y_test 데이터 4개를 가지고 학습
# 학습 .fit
regressor.fit( X_train, y_train )
# 방정식을 확인해 보기 위해서 상수(.intercept_) 와 계수(.coef_) 확인
# 상수
regressor.intercept_
25375.305271282858
# 학습된 계수를 가져와바 할때 .coef_
regressor.coef_
array([9504.98248109])
# y = 25375.305271282858 + 9504.98248109 * x
# 이게 학습된 방정식
# 학습이 끝나면, 이 인공지능이 얼마나 똑똑한지 테스트 해야 한다.
# 따라서, 테스트용 데이터인 X_test로 테스트 한다.
# 에측해줘 는 .predict() // 학습은 X,y 모두 기입해야 하지만, 예측은 평가 기준이 되는 X 데이터만 기입하면 된다.
regressor.predict(X_test)
array([ 71949.71942864, 55791.24921078, 53890.25271456, 115672.63884167,
44385.27023347, 63395.23519566])
# 실제 test용 y와 비교하기 위해 변수로 지정
y_pred = regressor.predict(X_test)
y_pred
array([ 71949.71942864, 55791.24921078, 53890.25271456, 115672.63884167,
44385.27023347, 63395.23519566])
# 실제 데이터와, 예측 데이터를 비교하면 된다.
# 오차(실제값 - 예측값)를 구한다!!
# 오차가 작으면, 똑똑한 인공지능을 만든것!
# 오차값
y_test - y_pred
15 -4011.719429
8 8653.750789
6 6259.747285
26 1296.361158
3 -860.270233
11 -7601.235196
Name: Salary, dtype: float64error = y_test - y_pred
# 오차를 제곱해서, 부호를 먼저 없앤 후에
# 평균을 구한다.
error ** 2
15 1.609389e+07
8 7.488740e+07
6 3.918444e+07
26 1.680552e+06
3 7.400649e+05
11 5.777878e+07
Name: Salary, dtype: float64(error ** 2).mean()
31727520.866778105# 두데이터를 합쳐야 하는데 판다스 시리즈는 일차원이라 합칠수가 없으므로 데이터프레임으로 만들고 합쳐줘야 한다.
y_test
15 67938.0
8 64445.0
6 60150.0
26 116969.0
3 43525.0
11 55794.0
Name: Salary, dtype: float64
# 판다스 시리즈를 데이터프레임으로 변환
df_test = y_test.to_frame()
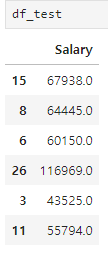
# y_pred 예측값을 실제값에 컬럼으로 삽입
df_test['y_pred'] = y_pred

# 표가 제대로 그려지지 않음 인덱스 순서가 뒤죽박죽이라
df_test.plot()
plt.show()

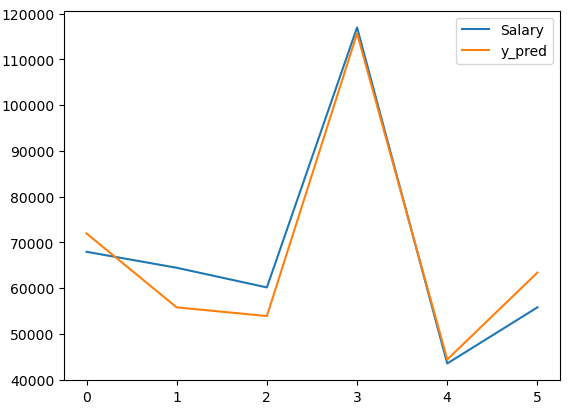
# 인덱스를 정리해줌
df_test.reset_index(drop=True, inplace=True)

# 이쁘게 그려지는걸 볼수 있다.
df_test.plot()
plt.show()
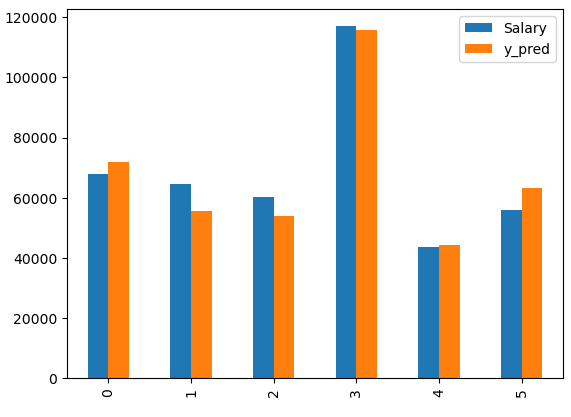
# bar 차트로 보려면
df_test.plot(kind='bar')
# 옆으로 누운바 df_test.plot(kind='barh')
plt.show()