
< Accessing Elements in Pandas DataFrames >
import pandas as pd
# We create a list of Python dictionaries
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5}]
< 데이터 액서스 : 굉장히 중요함 데이터 분석의 핵심!!!!! >
# 상단에서 생성한 items2 딕셔너리를 데이터프레임으로 변환
df = pd.DataFrame(data= items2, index= ['store 1', 'store 2'])
df

### 가장 중요한것!!! "데이터 프레임" 에서 원하는 데이터를 억세스 하는 방법
### 데이터 억세스 방법은 총 3가지!
1) 컬럼의 데이터를 가져오는 방법 : 변수명 바로 오른쪽에 대괄호 사용! => 그동안 사용했던 '변수명[ ]' 이 형태
df['watches']
store 1 35
store 2 10
Name: watches, dtype: int64ㄴ 해당 결과값과 같은 형태를 '시리즈'라고 칭하는 것이다. 기억할것! (1차원)
# 바이크랄 와치 컬럼 두개를 한번에 가져오시오
df[['bikes','watches']]

2) 행과 열의 정보로, 원하는 데이터를 가져오는 방법 (1)
## .loc[ , ] 로 가져오는 방법
## 이 방법은, 사람용인 인덱스와 컬럼으로 데이터를 억세스 하는 방법
# 스토어 1의 팬츠 데이터를 가져와라.

df.loc[ 'store 1' , 'pants' ]
30
# 스토어 2의 bikes 와 watches 데이터를 가져와라.
df.loc[ 'store 2' , ['bikes','watches'] ]
bikes 15.0
watches 20.0
Name: store 2, dtype: float64
# 스토어 2에서, pants 부터 glasses 까지 데이터를 가져와라.
df.loc[ 'store 2' , 'pants':'glasses']
pants 5.0
watches 20.0
glasses 50.0
Name: store 2, dtype: float64
3) 행과 열의 정보로 데이터를 가져오는 방법(2)
## .iloc[ , ]
## 이 방법은, 컴퓨터가 매기는 인덱스(오프셋 offset)로 데이터를 억세스 하는 방법
# 스토어1의 팬츠 데이터를 가져오시오.
df.iloc[ 0 , 1 ]
30
# 스토어2 의 bikes 와 watches 데이터를 가져와라.
df.iloc[ 1 , [0,2] ]
bikes 15.0
watches 10.0
Name: store 2, dtype: float64
# 스토어2에서 팬츠부터 글래시스 까지 데이터를 가져와라.
df.iloc[ 1 , 1:3+1 ]
pants 5.0
watches 10.0
glasses 50.0
Name: store 2, dtype: float64
# 스토어2의 데이터를 가져와라. (loc, iloc를 모두 활용)
# 열에는 : 을 써도 되고 안써도됨
df.loc[ 'store 2' , ]
bikes 15.0
pants 5.0
watches 10.0
glasses 50.0
Name: store 2, dtype: float64
df.iloc[ 1 , : ]
bikes 15.0
pants 5.0
watches 10.0
glasses 50.0
Name: store 2, dtype: float64
# watches 데이터를 가져와라 (인덱싱, .loc, .iloc 를 모두 활용)
df['watches']
store 1 35
store 2 10
Name: watches, dtype: int64
df.loc[ : , 'watches' ]
store 1 35
store 2 10
Name: watches, dtype: int64
df.iloc[ : , 2 ]
store 1 35
store 2 10
Name: watches, dtype: int64
< 데이터의 값을 변경 >
# 스토어 2의 watches 데이터를, 20으로 변경하라.
df.iloc[ 1 , 2 ] = 20
df

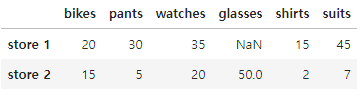
# 새로운 품목을 팔기로 했다.
# shirts 라는 컬럼을 만들고, store 1에는 15개, store 2에는 2개를 만들어라.
# 컬럼 만드는 방법 (numpy 처럼 append를 따로 사용안해도 된다.)
df['shirts'] = [ 15, 2 ]
df

# suits 컬럼을 만들건데,
# pants 컬럼의 값과 shirts 컬럼의 값을 더해서 만들자.
df['suits'] = df['pants'] + df['shirts']
df
< 데이터 삽입 >
# 실무에서 많이 쓰이지는 않지만 종종 새로운 데이터 값을 삽입해야 하는 경우가 생긴다.
# 이떄 사용하는 방법 .concat
# 상입할 데이터를 딕셔너리로 생성하고, 데이터 프레임워크로 변환
new_item = [ {'bikes' : 20, 'pants' : 30, 'watches' : 35, 'glasses' : 4} ]
new_store_df = pd.DataFrame(data= new_item, index= ['store 3'])
# 기존 df 데이터에 .concat을 사용하여 데이터 삽입
df = pd.concat( [df, new_store_df] )
df

ㄴ NaN 은 해당 항목에 값이 없음을 뜻합니다. (Not a Number)
다음 게시글에서 계속
'PYTHON LIBRARY > Pandas Library' 카테고리의 다른 글
| Python Pandas로 결측치 데이터 처리하기: NaN 처리 isna(), notna(), dropna(), fillna() (0) | 2024.04.11 |
|---|---|
| Python Pandas 데이터프레임 조작 : 행/열 삭제부터 이름/타입 변경까지 drop() 함수 , rename({}) 함수 (0) | 2024.04.10 |
| Python Pandas로 데이터 분석 시작하기 : DataFrame 기초 (0) | 2024.04.09 |
| Python Pandas로 데이터 처리하기 : 시리즈의 레이블 접근과 산술 연산 (0) | 2024.04.08 |
| Python Pandas로 시작하는 데이터 분석 : Series 데이터 생성 pd.Series() (2) | 2024.04.08 |