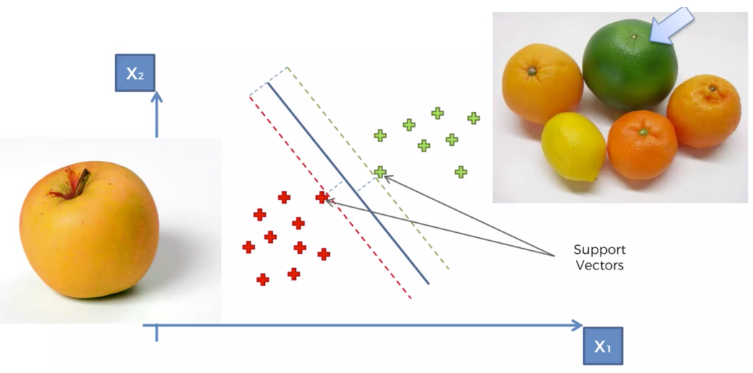
# Support Vector Machine (SVM)은 지도 학습 알고리즘 중 하나로, 데이터를 분류하기 위한 최적의 결정 경계(decision boundary)를 찾는 것을 목표로 한다.아래의 3개 의 선 모두, 분류하는 선이 모두 맞다. 그러면 어떤것이 더 정확할까?분류선에 가장 가까운 데이터들을, 가장 큰 마진(margin)으로 설정하는 선으로 결정하자.분류선을 Maximum Margin Classifer 라고 한다.SVM은 다른 머신러닝 알고리즘과 비교해서 무엇이 특별한가?사과인지 오렌지인지 분석하는 문제일반적인 사과와 오렌지들은, 클래서파이어에서 멀리 분포한다.정상적이지 않은 것들, 즉 구분하기 힘든 부분에 있는 것들은 클래서파이어 근처에 있게 되며,이 데이터들이 레이블링 되어 있으므로, Ma..