
< pandas의 pivot_table 익히기 >
- 바로 이전 프로젝트 연습예제문을 이어서 진행
# 구이름을 인덱스로 만들려는데
# 인덱스는 유니크해야 하므로 구이름이 중복된 값은 모든 데이터 값을 합친다
# 그러기 위한 방법이 pivot_table ( 데이터프레임의 데이터를 피벗하여 요약하는 데 사용)
import pandas as pd
import numpy as np
# 피봇팅 한다. 즉 컬럼의 값을 인덱스로 만들되,
# 인덱스를 중복제거하여 유니크 하게 만드는 방법
# 새로운 데이터로 코딩 한다.
df_test = pd.read_excel('../data/sales-funnel.xlsx')
df_test
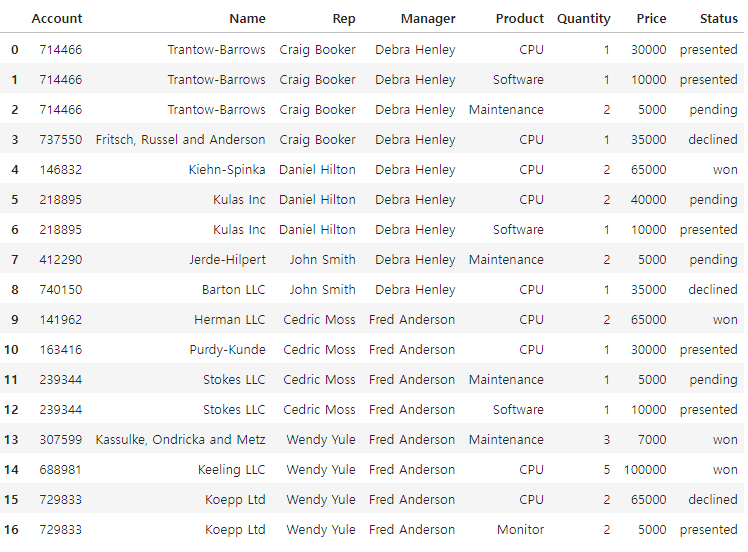
# Name 열을 가지고 하나로 합쳐서 인덱스로 만들고 싶을때
#기본적으로 동일한 데이터를 합칠때, 숫자 데이터를 default 평균으로 출력한다
pd.pivot_table(df_test, index= ['Name'], values = ['Quantity' , 'Price'])

#숫자 데이터를 합하여 출력하고 싶다
pd.pivot_table(df_test, index= ['Name'], values = ['Quantity' , 'Price'], aggfunc= 'sum')
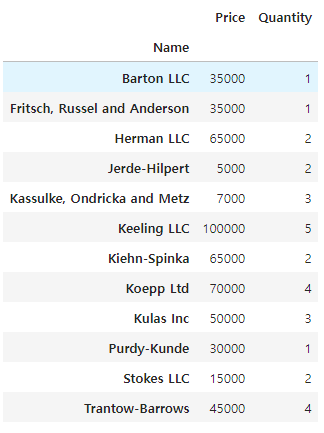
# Prodeuct 를 인덱스로 하고 price의 최대값을 보자
pd.pivot_table(data= df_test, index= ['Product' , 'Rep'], values = ['Price'], aggfunc=['max','min'])
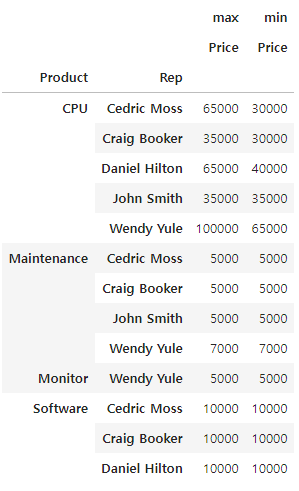
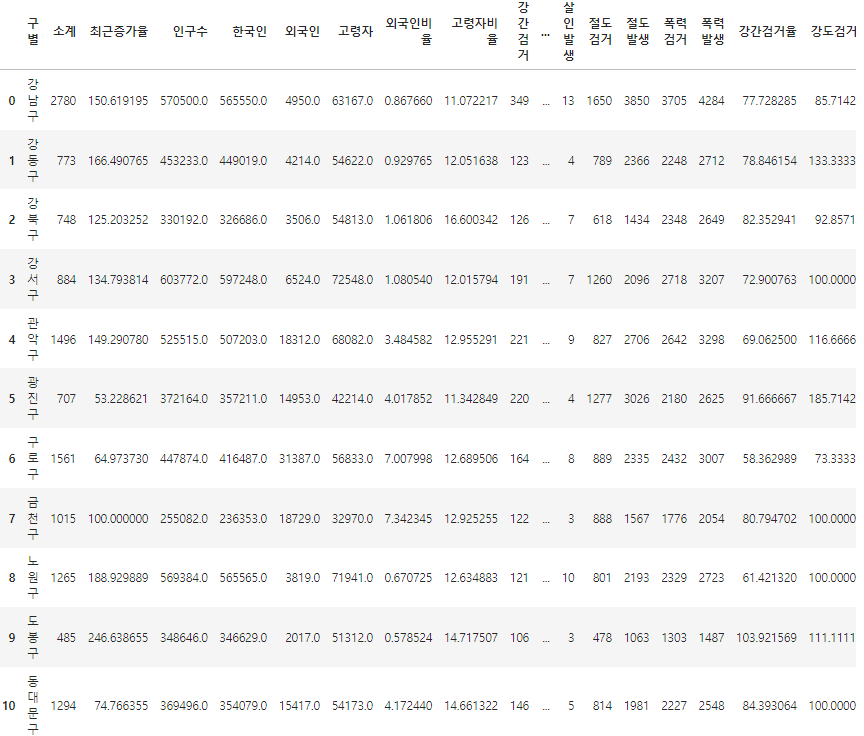
# 이제 피벗테이블을 이전에 실습하던 범죄데이터에 적용해 보자.
# 범죄 데이터 구별로 정리하기
# 피봇으로 합칠때 문자열은 합치는게 불가능 하다. 그러므로 문자열인 관서명은 삭제한다
crime_anal = df.drop('관서명', axis=1)
crime_anal

# 구별로 모든 범죄 데이터의 합 => 만약의 함수를 하나만 쓸거면 aggfunc= 뒤에 [] 를 지워도 되고, 여러 함수를 쓸거면 [] 안에 적어야함
crime_anal = pd.pivot_table(data= crime_anal, index=['구이름'], aggfunc='sum')
crime_anal

실습 4) 인덱스를 '구별' 로 피봇팅 한다.
crime_anal.reset_index(inplace=True)
crime_anal.rename(columns={'구이름' : '구별'}, inplace=True)
crime_anal

crime_anal = pd.merge(df_cctv, crime_anal, on='구별')
crime_anal

ㄴ 데이터 24행 까지 있음
실습 5) '강간검거율' , '강도검거율', '살인검거율', '절도검거율', '폭력검거율' 을 계산하여, crime_anal에 각 컬럼을 추가한다. ( 검거율은 * 100 까지 한 값)
crime_anal['강간검거율'] = crime_anal['강간 검거'] / crime_anal['강간 발생'] * 100
crime_anal['강도검거율'] = crime_anal['강도 검거'] / crime_anal['강도 발생'] * 100
crime_anal['살인검거율'] = crime_anal['살인 검거'] / crime_anal['살인 발생'] * 100
crime_anal['절도검거율'] = crime_anal['절도 검거'] / crime_anal['절도 발생'] * 100
crime_anal['폭력검거율'] = crime_anal['폭력 검거'] / crime_anal['폭력 발생'] * 100
crime_anal
실습 6) 이제 필요없는, '강간 검거' , '강도 검거', '살인 검거', '절도 검거', '폭력 검거' 컬럼을 제거한다.
crime_anal = crime_anal.drop(['강간 검거','강도 검거','살인 검거','절도 검거','폭력 검거'], axis=1)
crime_anal

실습 7) describe() 함수로 값을 확인해 보니, 검거율이 100 이상인 경우도 있다. 따라서 100보다 크면, 100으로 값을 셋팅하세요.
crime_anal.describe()
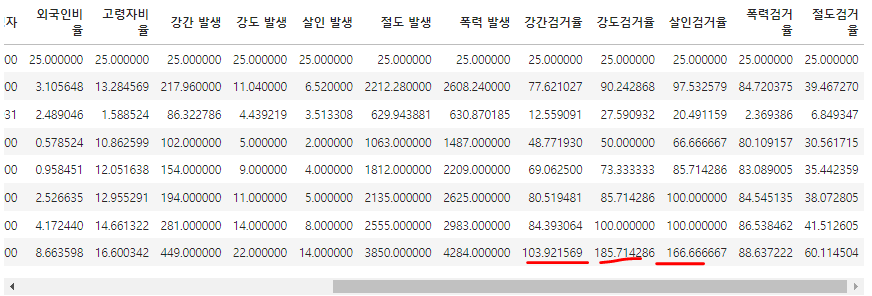
ㄴ 작년에 발생된 범죄를 올해 검거할수도 있고, 발생시기와 검거시기가 달라서 데이터에 오류가 생긴것
ㄴ 이렇기 때문에 데이터 가공 중간중간 검토가 필수
crime_anal.loc[crime_anal['강간검거율'] >= 100 , '강간검거율' ] = 100
crime_anal.loc[crime_anal['강도검거율'] >= 100 , '강도검거율' ] = 100
crime_anal.loc[crime_anal['살인검거율'] >= 100 , '살인검거율' ] = 100
crime_anal.describe()

실습 8) 강간 발생, 강도 발생, 살인 발생, 절도 발생, 폭력 발생 의 컬럼 명을, 강간, 강도, 살인, 절도, 폭력으로 rename 하세요.
crime_anal.rename( columns= { '강간 발생' : '강간' , '강도 발생' : '강도', '살인 발생' : '살인', '절도 발생' : '절도', '폭력 발생' : '폭력' }, inplace=True)

실습 9) 강간, 강도, 살인, 절도, 폭력 을 피처스케일링 중 노멀라이징 합니다.
데이터 노멀라이징 하는 이유는, 각각의 레인지를 통일하여, 해석하기 쉽게 하기 위함입니다.
# 파이썬에서 머신러닝 관련된 라이브러리 sklearn
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 표준화와 정규화 를 통해 피처스케일링
# 데이터와 데이터간의 범위를 맞춰주기 위해서 시행하는 방법 다만, 머신러닝을 시키기위해서 해당 두가지 방법으로 시행한다.
# 중요한것은 컬럼과 컬럼간에 데이터들을 비교하는것! 이걸 위해서 피처스케일링이 필요하다.
# 라이브러리를 우선 변수로 만들어줘야 한다. 메모리에 업로드
# (1) 표준화
s_scaler = StandardScaler()
# 피처스케일링 => .fit_transform()
s_scaler.fit_transform( crime_anal.loc[ : , '강간' : '폭력'] )
array([[ 2.73165666, 2.28990327, 1.88244875, 2.65339664, 2.71104172],
[-0.73257205, -1.15874623, -0.7320634 , 0.24905364, 0.16786275],
[-0.76804197, 0.6805335 , 0.13944065, -1.26095153, 0.06594146],
[ 0.5206984 , 0.45062353, 0.13944065, -0.18839421, 0.96867292],
[ 1.20645016, 0.22071357, 0.72044335, 0.7999139 , 1.11589257],
[ 0.26058567, 0.6805335 , -0.7320634 , 1.31837061, 0.0271143 ],
[ 0.74534122, 0.91044347, 0.429942 , 0.19882815, 0.64511326],
[-0.79168858, -1.15874623, -1.02256475, -1.04546796, -0.89664854],
[-0.2478165 , -0.92883626, 1.0109447 , -0.03123702, 0.18565854],
[-1.37103059, -0.46901633, -1.02256475, -1.86203728, -1.81394019],
[-0.53157585, 0.45062353, -0.44156205, -0.37471459, -0.09745617],
[ 0.79263445, -0.46901633, -0.44156205, -0.56265515, -1.1296115 ],
[ 0.8990442 , 0.6805335 , 0.429942 , 0.55526714, 0.6062861 ],
[-0.75621866, -1.3886562 , -1.3130661 , -0.64852454, -0.89341295],
[ 2.06955151, -0.46901633, 0.429942 , 0.68488131, -0.33850812],
[-1.08727124, -0.46901633, -0.7320634 , -0.98066087, -1.6117154 ],
[-0.80351189, -1.3886562 , -0.44156205, -0.69226932, -0.6458898 ],
[ 0.02411954, 0.45062353, 1.30144605, 1.66346836, 1.11103918],
[-1.15821107, -1.15874623, -1.02256475, -0.52215071, -0.16055031],
[ 0.91086751, 2.51981323, 2.1729501 , 1.21791962, 1.55916931],
[-0.28328642, 0.6805335 , -0.44156205, -1.06166973, -0.90311974],
[-0.61433899, -0.46901633, -1.02256475, -0.48326646, 0.07241265],
[-0.08229021, -0.0091964 , -0.1510607 , -0.04581861, -0.50999474],
[-0.56704576, -0.46901633, -1.02256475, 0.5439259 , -0.62162283],
[-0.36604956, -0.0091964 , 1.88244875, -0.1252073 , 0.38626553]])ㄴ 머신러닝 라이브러리로 실행하였기 때문에 결과는 numpy로 출력된다. 머신러닝은 numpy로 동작
# (2) 정규화
m_scaler = MinMaxScaler()
m_scaler.fit_transform( crime_anal.loc [ : , '강간' : '폭력' ] )
array([[1. , 0.94117647, 0.91666667, 1. , 1. ],
[0.1556196 , 0.05882353, 0.16666667, 0.46752781, 0.43796925],
[0.14697406, 0.52941176, 0.41666667, 0.13311805, 0.41544512],
[0.4610951 , 0.47058824, 0.41666667, 0.37064944, 0.61494458],
[0.62824207, 0.41176471, 0.58333333, 0.58952278, 0.64747944],
[0.39769452, 0.52941176, 0.16666667, 0.70434159, 0.4068645 ],
[0.51585014, 0.58823529, 0.5 , 0.45640474, 0.5434394 ],
[0.14121037, 0.05882353, 0.08333333, 0.18083961, 0.2027172 ],
[0.27377522, 0.11764706, 0.66666667, 0.40545389, 0.44190204],
[0. , 0.23529412, 0.08333333, 0. , 0. ],
[0.20461095, 0.47058824, 0.25 , 0.32938644, 0.379335 ],
[0.52737752, 0.23529412, 0.25 , 0.28776462, 0.15123346],
[0.55331412, 0.52941176, 0.5 , 0.53534266, 0.53485878],
[0.14985591, 0. , 0. , 0.26874776, 0.20343225],
[0.83861671, 0.23529412, 0.5 , 0.56404736, 0.32606364],
[0.06916427, 0.23529412, 0.16666667, 0.19519196, 0.04469074],
[0.13832853, 0. , 0.25 , 0.25905992, 0.25813371],
[0.34005764, 0.47058824, 0.75 , 0.78076785, 0.64640686],
[0.0518732 , 0.05882353, 0.08333333, 0.29673484, 0.36539149],
[0.55619597, 1. , 1. , 0.68209544, 0.74544154],
[0.26512968, 0.52941176, 0.25 , 0.17725152, 0.20128709],
[0.18443804, 0.23529412, 0.08333333, 0.30534625, 0.41687522],
[0.31412104, 0.35294118, 0.33333333, 0.40222461, 0.28816589],
[0.19596542, 0.23529412, 0.08333333, 0.532831 , 0.2634966 ],
[0.24495677, 0.35294118, 0.91666667, 0.38464299, 0.48623525]])
# 이번 예제문에선 정규화한 값을 사용 // 정규화한 값을 데이터에 넣어준다.
crime_anal.loc[:,'강간':'폭력'] = m_scaler.fit_transform( crime_anal.loc[:,'강간':'폭력'])
실습 10) 강간, 강도, 살인, 절도, 폭력 의 값을 모두 더하고, 이 더한값을 '범죄' 라는 컬럼을 만들어서 넣습니다.
crime_anal.columns
Index(['구별', '소계', '최근증가율', '인구수', '한국인', '외국인', '고령자', '외국인비율', '고령자비율', '강간',
'강도', '살인', '절도', '폭력', '강간검거율', '강도검거율', '살인검거율', '폭력검거율', '절도검거율'],
dtype='object')
# 분석에 필요없는 컬럼은 제거해 주자.
crime_anal.drop(['최근증가율', '인구수', '한국인', '외국인', '고령자'] , axis=1, inplace=True)
# 소계 컬럼은 CCTV의 수를 나타내는 것이므로 알아보기 쉽게 컬럼명 변경
crime_anal.rename(columns={'소계' : 'CCTV'}, inplace=True)
# 인덱스를 '구별'로 설정하여 저장
crime_anal.set_index('구별', inplace=True)
# 기본 가공이 끝났으니 문제 예제 실행
crime_anal['범죄'] = crime_anal['강간'] + crime_anal['강도'] + crime_anal['살인'] + crime_anal['절도'] + crime_anal['폭력']
crime_anal

실습 11) '강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율' 의 값을 모두 더하고, 이 더한값을 '검거' 라는 컬럼을 만들어서 넣습니다.
crime_anal['검거'] = crime_anal['강간검거율'] + crime_anal['강도검거율'] + crime_anal['살인검거율'] + crime_anal['절도검거율'] + crime_anal['폭력검거율']
crime_anal

< Visualization using seaborn >
실습 12) sb의 pairplot 으로 "강도", "살인", "폭력" 을 나타내세요. (연관성 확인)
crime_anal[['강도','살인','폭력']].corr()

# 시각화 해보자
import matplotlib.pyplot as plt
import seaborn as sb
# 3개 컬럼을 넣을경우 (1,3) (2,3) (1,3) 관계를 다 보여줌
sb.pairplot(data= crime_anal, vars= ['강도' , '살인', '폭력'])
plt.show()

실습 13) x_vars는 "인구수", "CCTV" 를, y_vars는 "살인", "강도"로 pariplot을 나타내고, 연관성을 확인하세요.
sb.pairplot(data=crime_anal, x_vars= ["인구수", "CCTV"], y_vars=[ "살인", "강도","강간"])
plt.show()

# 해당 그래프 만으로는 관계성을 알아보기 어렵기 때문에 상관계수가 필요한것
crime_anal[['인구수','CCTV','살인','강도','강간']].corr()

실습 14. x_vars는 "인구수", "CCTV" 를, y_vars는 "살인검거율", "폭력검거율"로 pariplot을 나타내고, 연관성을 확인하세요.
# pairplot 에도 regplot 처럼 선을 나타내는 방법이 있다. kind = 'reg' 를 입력
sb.pairplot(data=crime_anal, x_vars= ["인구수", "CCTV"], y_vars=[ "살인검거율", "폭력검거율","절도검거율"] , kind='reg')
plt.show()

crime_anal[['인구수','CCTV','살인검거율','폭력검거율','절도검거율']].corr()

실습 15) 검거가 가장 높은 구는 어디입니까? 이를 확인하기 위해, 검거가 가장 높은 구부터 정렬하여 5개의 구까지 나타내세요.
crime_anal.sort_values('검거', ascending=False).head()

실습 16) 검거가 가장 큰값이 432.593167 입니다. 검거의 값이 최대가 100이 되도록 정규화를 하세요. 그리고 검거값으로 정렬하세요.
catch = (crime_anal['검거'] - crime_anal['검거'].min()) / (crime_anal['검거'].max() - crime_anal['검거'].min()) * 100
crime_anal.loc[ : , '검거'] = catch
crime_anal.sort_values('검거', ascending=False).head()


# 강사님 풀이
crime_anal['검거'] = crime_anal['검거'] / crime_anal['검거'].max() * 100
crime_anal.sort_values('검거' ,ascending=False).head()

실습 17) sb.heatmap 을 이용해서 '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' 을 보여주세요. 단, '검거' 로 정렬한 데이터로 보여주세요.
# 데이터프레임에 value 부분의 숫자를 색으로 표시하고 싶을때
# sb.heatmap 함수를 사용한다. // plt.hist2d 랑은 다르다. hist2d는 두컬럼간의 관계를 나타내는것 => 상황마다 사용하는것이 다르니 외워둘것
# 검거로 정렬하라고 하였으니 검거 정렬값을 변수로 지정
df5 = crime_anal.sort_values('검거' ,ascending=False)
# 실제 차트로 그릴 데이터를 가져와서 변수로 지정
df6 = df5.loc [ : , '강간검거율' : '절도검거율' ]
df6

# 이제 해당 데이터를 색으로 표시하자
# sb.heatmap( data , camp= '색깔', annot=True (숫자로 표시) , fmt=' .1f' (숫자 형식 지정), linewidths=0.8 (칸들간에 거리)
# figure. figsize는 차트 크기 (행 열 크기 지정)
plt.figure(figsize=(10,8))
sb.heatmap(data=df6, cmap='RdPu', annot=True, fmt=' .1f', linewidths=0.8)
plt.show()

실습 18) 위에서 배운 히트맵을 이용해서, 살기 무서운 구가 어디인지 분석하세요.
# 범죄율이 가장 높은 구가 살기 무서운구일것이니 범죄로 정렬해보자
# 정렬 기준은 '범죄' 차트로 그릴 데이터는 강간~폭력 발생율
df7 = crime_anal.sort_values('범죄', ascending=False).loc[ : , '강간' : '폭력' ]
df7

plt.figure(figsize=(10,8))
sb.heatmap(data=df7, cmap='RdPu', annot=True, fmt=' .1f', linewidths=0.8)
plt.show()

프로젝트 범죄데이터 실습 종료
'PYTHON LIBRARY > Project 연습 (새로운 개념 정리 추가!)' 카테고리의 다른 글
| 프로젝트(범죄현황) 연습(1) : 데이터 주무르기, API 키 생성 활용(googlemaps.Client()) (3) | 2024.04.18 |
|---|---|
| 프로젝트(CCTV설치) 연습 : 데이터를 분석 가공하여 상관관계 분석(.corr())과 데이터 시각화까지 (0) | 2024.04.17 |
| 프로젝트(대중교통) 연습 : 데이터를 분석하여 파이차트 그리기 plt.pie() (0) | 2024.04.17 |
| 프로젝트(기온데이터분석) 연습 : 데이터 가공하여 히스토그램, 산점도 그리기 plt.hist() , plt.scatter() (0) | 2024.04.16 |