
레퍼런스 : 파이썬으로 데이터 주무르기
# 이전장에서 사용했던 CCTV 데이터 불러와서 시작
df_cctv = pd.read_csv('../데이터분석2/CCTV_result.csv')
df_cctv
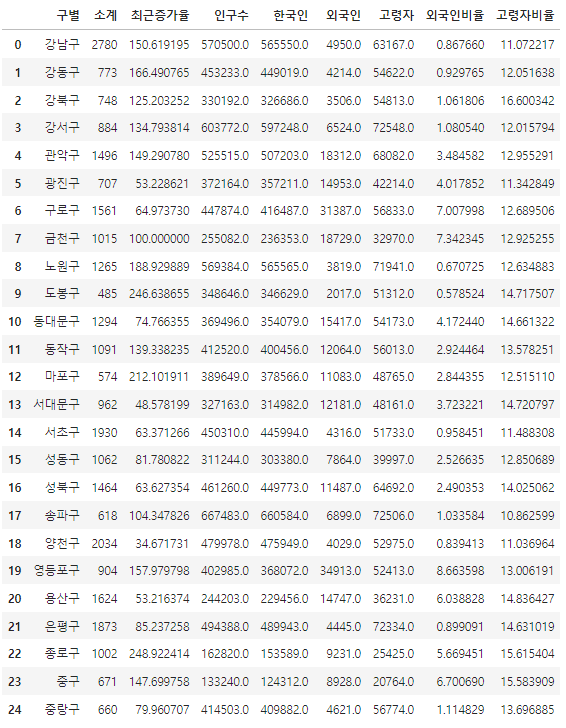
서울시 구별 범죄 발생과 검거율 데이터 분석
'서울시 관서별 5대 범죄 발생 검거 현황' 파일을 가지고 분석합니다.
# 한글 찍기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')
실습 1) crime_in_Seoul.csv 파일을 pandas 로 읽어오세요.
한글이 깨지지 않도록 encoding='euc-kr' 옵션을 넣습니다.
df = pd.read_csv('../data/crime_in_Seoul.csv', encoding='euc-kr')
df

# 통계 분석
df.describe()
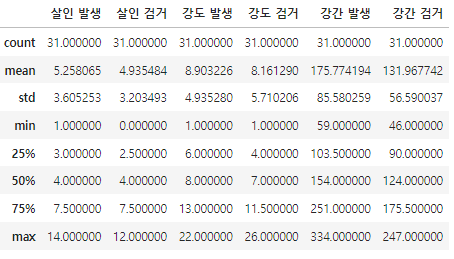
ㄴ 절도발생, 절도 검거, 폭력 발생, 폭력 검거 4가지가 안나온걸 볼수있다. 쉼표(,) 때문에 문자열로 인식한것
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 31 entries, 0 to 30
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 관서명 31 non-null object
1 살인 발생 31 non-null int64
2 살인 검거 31 non-null int64
3 강도 발생 31 non-null int64
4 강도 검거 31 non-null int64
5 강간 발생 31 non-null int64
6 강간 검거 31 non-null int64
7 절도 발생 31 non-null object
8 절도 검거 31 non-null object
9 폭력 발생 31 non-null object
10 폭력 검거 31 non-null object
dtypes: int64(6), object(5)
memory usage: 2.8+ KBㄴ object 타입인걸 볼수있다.
# 이럴땐 숫자로 변경해줘야 한데 데이터를 불러올때
# thousands=',' 을넣어주면 쉼표를 자동으로 제거해 준다.
df = pd.read_csv('../data/crime_in_Seoul.csv', encoding='euc-kr', thousands=',')
df

# 이제 전체 데이터에대한 결과값이 나오는걸 볼수 있다.
df.describe()

실습 2) 경찰서들은 하나의 구에 여러개가 있을 수 있습니다. 따라서 우리는 구 단위로 데이터를 통합하겠습니다.
실습 2-1. 경찰서가 무슨 구에 있는지 확인하기 위해, 구글맵 API를 이용하겠습니다.
구글맵 API를 이용하기 위해서는 구글맵 라이브러리를 설치합니다.
아나콘다 프롬프트 실행 후, pip install googlemaps 실행
import googlemaps
! pip install googlemaps
Defaulting to user installation because normal site-packages is not writeable
Collecting googlemaps
Downloading googlemaps-4.10.0.tar.gz (33 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Requirement already satisfied: requests<3.0,>=2.20.0 in c:\programdata\anaconda3\lib\site-packages (from googlemaps) (2.31.0)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\programdata\anaconda3\lib\site-packages (from requests<3.0,>=2.20.0->googlemaps) (2.0.4)
Requirement already satisfied: idna<4,>=2.5 in c:\programdata\anaconda3\lib\site-packages (from requests<3.0,>=2.20.0->googlemaps) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in c:\programdata\anaconda3\lib\site-packages (from requests<3.0,>=2.20.0->googlemaps) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in c:\programdata\anaconda3\lib\site-packages (from requests<3.0,>=2.20.0->googlemaps) (2024.2.2)
Building wheels for collected packages: googlemaps
Building wheel for googlemaps (setup.py): started
Building wheel for googlemaps (setup.py): finished with status 'done'
Created wheel for googlemaps: filename=googlemaps-4.10.0-py3-none-any.whl size=40746 sha256=679ba0ab1a628c9bc2f6a57372e60dfc4d4b5054160dcb56a569f5fc1f1adda7
Stored in directory: c:\users\406\appdata\local\pip\cache\wheels\f1\09\77\3cc2f5659cbc62341b30f806aca2b25e6a26c351daa5b1f49a
Successfully built googlemaps
Installing collected packages: googlemaps
Successfully installed googlemaps-4.10.0
Note: you may need to restart the kernel to use updated packages.
실습 2-2) 구글 클라우드의 MAPS API 페이지로 이동하여, API 키를 생성합니다.
https://cloud.google.com/maps-platform/?hl=ko
콘솔로 이동 => Geocoding API 선택 => 사용자인증정보 에서 API 키 생성
# API에서 자료를 바로 사용할수 있는것이 아니고 인증에 필요한 API 키를 생성하여 요청하여야한다.
# 구글 회원가입 후에 구글 클라우드에서 API 키 생성 및 지오코딩 api 사용허가로 설정하여야 한다.


- 구글 맵스를 사용해서 경찰서의 위치(위도, 경도) 정보를 받아온다
# 구글 map 사용을 위해서 신규 import
import googlemaps
# goolgle 에서 생성한 API를 삽입후 해당 클라이언틀르 사용하도록 변수로 지정
gmaps_key = "AIzaSyCa8mZ_WKOcAdl3tyHlRXY8O8csUb2LOlI" # 자신의 key를 사용합니다.
gmaps = googlemaps.Client(key=gmaps_key)
# 실제사용 데이터를 변수로 저장
response = gmaps.geocode('서울종로경찰서', language='ko')
response
[{'address_components': [{'long_name': '41',
'short_name': '41',
'types': ['premise']},
{'long_name': '인사동5길',
'short_name': '인사동5길',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '종로구',
'short_name': '종로구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '110-160',
'short_name': '110-160',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 종로구 인사동5길 41',
'geometry': {'location': {'lat': 37.571824, 'lng': 126.9841533},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5731729802915,
'lng': 126.9855022802915},
'southwest': {'lat': 37.5704750197085, 'lng': 126.9828043197085}}},
'partial_match': True,
'place_id': 'ChIJRVgVHsOifDURFhKFchVo22I',
'plus_code': {'compound_code': 'HXCM+PM 대한민국 서울특별시',
'global_code': '8Q98HXCM+PM'},
'types': ['establishment', 'point_of_interest', 'police']}]ㄴ 이런 결과값 형태를 json(리스트와 딕셔너리의 조합) 이라 한다.
# 'formatted_address': '대한민국 서울특별시 중구 수표로 27', 해당 내용이 실제 변경된 결과값이므로 여기에서 필요한 중구만 가져온다
# 구조파악 list안에 딕셔너리가 들어있음
# 해당 리스트에서 딕셔너리를 뺴와서 필요한 인덱스를 split 통해 불러온다.
# 변수로 저장
gu_name = response[0]['formatted_address'].split()[2]
# 관서명의 데이터에서, 왼쪽에는 서울, 오른쪽에는 '서' 없이 '경찰서'를 붙이는 작업
'서울' + df['관서명'].str[ 0 : -2+1 ] + '경찰서'
0 서울중부경찰서
1 서울종로경찰서
2 서울남대문경찰서
3 서울서대문경찰서
4 서울혜화경찰서
5 서울용산경찰서
6 서울성북경찰서
7 서울동대문경찰서
8 서울마포경찰서
9 서울영등포경찰서
10 서울성동경찰서
11 서울동작경찰서
12 서울광진경찰서
13 서울서부경찰서
14 서울강북경찰서
15 서울금천경찰서
16 서울중랑경찰서
17 서울강남경찰서
18 서울관악경찰서
19 서울강서경찰서
20 서울강동경찰서
21 서울종암경찰서
22 서울구로경찰서
23 서울서초경찰서
24 서울양천경찰서
25 서울송파경찰서
26 서울노원경찰서
27 서울방배경찰서
28 서울은평경찰서
29 서울도봉경찰서
30 서울수서경찰서
Name: 관서명, dtype: object
# 이전 '관서명' 컬럼 내용을 해당 내용으로 바꿔주자
df['관서명'] = '서울' + df['관서명'].str[ 0 : -2+1 ] + '경찰서'

실습 3-1) station_addreess 에 저장된 주소에서, 구만 따로 띄어냅니다. (예, 종로구)
따로 띄어낸 구를, crime_anal_police 에 '구별' 컬럼을 만들어서 넣습니다.
# 상단에서짠 해당 로직을 df '관서명'에 적용하고 싶다. => apply
# 그러려면 우선 함수로 만들어야 한다
def get_gu_name(name) :
import googlemaps
gmaps_key = "AIzaSyCa8mZ_WKOcAdl3tyHlRXY8O8csUb2LOlI" # 자신의 key를 사용합니다.
gmaps = googlemaps.Client(key=gmaps_key)
response = gmaps.geocode(name, language='ko')
gu_name = response[0]['formatted_address'].split()[2]
return gu_name
get_gu_name('서울종로경찰서')
# 종로구가 나오게 함수를 짠다 => 코드 여러줄을 한줄로 만드는것
'종로구'
# 주소지가 바뀌거나 명칭이 바뀔경우 다른 결과값이 나올수 있음 26번처럼
df['관서명'].apply( get_gu_name )
0 중구
1 종로구
2 중구
3 서대문구
4 종로구
5 용산구
6 성북구
7 동대문구
8 마포구
9 영등포구
10 성동구
11 동작구
12 광진구
13 은평구
14 강북구
15 금천구
16 중랑구
17 강남구
18 관악구
19 강서구
20 강동구
21 성북구
22 구로구
23 서초구
24 양천구
25 송파구
26 노원경찰서
27 서초구
28 은평구
29 도봉구
30 강남구
Name: 관서명, dtype: object
# 노원구가 아니라 '서울노원경찰서'로 나오는걸 볼수있다.
df['관서명'][26]
'서울노원경찰서'
# 우선 결과값을 컬럼으로 넣는다
df['구이름'] = df['관서명'].apply( get_gu_name )

# 잘못된값은 직접 변경해줘야 한다
df.loc[26 , '구이름' ] = '노원구'
실습 3-2) crime_anal_police 데이터프레임을, csv 파일로 저장합니다.
저장할 파일명은 new_crime_in_Seoul.csv 로 저장하세요.
저장하는 함수는, 데이터프레임의 to_csv 입니다.
df.to_csv('new_crime_in_Seoul.csv')
ㄴ 저장된 파일 확인
다음 게시글에서 같은 프로젝트 문제로 이어서 진행
'PYTHON LIBRARY > Project 연습 (새로운 개념 정리 추가!)' 카테고리의 다른 글
| 프로젝트(범죄현황) 연습(2) : Pandas pivot_table 익혀서 범죄 데이터에 적용 및 데이터 시각화 (0) | 2024.05.03 |
|---|---|
| 프로젝트(CCTV설치) 연습 : 데이터를 분석 가공하여 상관관계 분석(.corr())과 데이터 시각화까지 (0) | 2024.04.17 |
| 프로젝트(대중교통) 연습 : 데이터를 분석하여 파이차트 그리기 plt.pie() (0) | 2024.04.17 |
| 프로젝트(기온데이터분석) 연습 : 데이터 가공하여 히스토그램, 산점도 그리기 plt.hist() , plt.scatter() (0) | 2024.04.16 |