
# 실습전 기본 라이브러리 및 한글 찍기 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')
실습 1) CCTV_in_Seoul.csv 파일을 pandas 로 읽어오세요.
encoding 은 'utf-8'
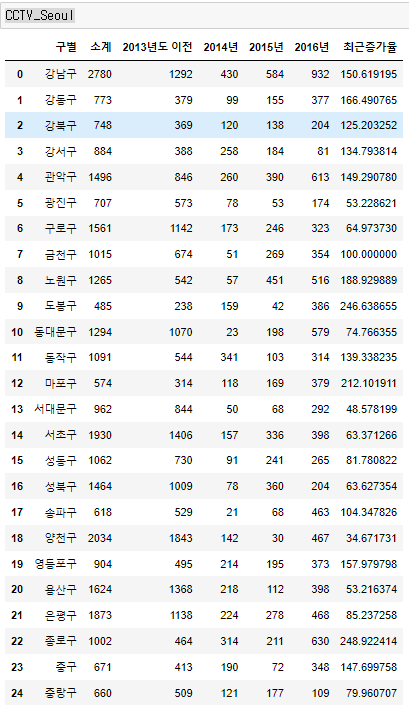
CCTV_Seoul = pd.read_csv('../data/CCTV_in_Seoul.csv')
CCTV_Seoul

실습 2) 컬럼 중 "기관명" 컬럼명을 "구별" 로 이름을 바꾸세요.
# rename(columns={'' : ''}) 함수 사용
CCTV_Seoul.rename(columns={'기관명': '구별'}, inplace=True)
실습 3) population_in_Seoul.xls 파일을 읽으세요.
# csv 파일이 아니라 xls 엑셀 파일이다. read_excel로 불러온다
pd.read_excel('../data/population_in_Seoul.xls')
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\compat\_optional.py:132, in import_optional_dependency(name, extra, errors, min_version)
131 try:
--> 132 module = importlib.import_module(name)
133 except ImportError:
File C:\ProgramData\anaconda3\Lib\importlib\__init__.py:126, in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1204, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:1176, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:1140, in _find_and_load_unlocked(name, import_)
ModuleNotFoundError: No module named 'xlrd'
During handling of the above exception, another exception occurred:
ImportError Traceback (most recent call last)
Cell In[14], line 1
----> 1 pd.read_excel('../data/population_in_Seoul.xls')
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\io\excel\_base.py:504, in read_excel(io, sheet_name, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, parse_dates, date_parser, date_format, thousands, decimal, comment, skipfooter, storage_options, dtype_backend, engine_kwargs)
502 if not isinstance(io, ExcelFile):
503 should_close = True
--> 504 io = ExcelFile(
505 io,
506 storage_options=storage_options,
507 engine=engine,
508 engine_kwargs=engine_kwargs,
509 )
510 elif engine and engine != io.engine:
511 raise ValueError(
512 "Engine should not be specified when passing "
513 "an ExcelFile - ExcelFile already has the engine set"
514 )
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\io\excel\_base.py:1580, in ExcelFile.__init__(self, path_or_buffer, engine, storage_options, engine_kwargs)
1577 self.engine = engine
1578 self.storage_options = storage_options
-> 1580 self._reader = self._engines[engine](
1581 self._io,
1582 storage_options=storage_options,
1583 engine_kwargs=engine_kwargs,
1584 )
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\io\excel\_xlrd.py:44, in XlrdReader.__init__(self, filepath_or_buffer, storage_options, engine_kwargs)
32 """
33 Reader using xlrd engine.
34
(...)
41 Arbitrary keyword arguments passed to excel engine.
42 """
43 err_msg = "Install xlrd >= 2.0.1 for xls Excel support"
---> 44 import_optional_dependency("xlrd", extra=err_msg)
45 super().__init__(
46 filepath_or_buffer,
47 storage_options=storage_options,
48 engine_kwargs=engine_kwargs,
49 )
File C:\ProgramData\anaconda3\Lib\site-packages\pandas\compat\_optional.py:135, in import_optional_dependency(name, extra, errors, min_version)
133 except ImportError:
134 if errors == "raise":
--> 135 raise ImportError(msg)
136 return None
138 # Handle submodules: if we have submodule, grab parent module from sys.modules
ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 2.0.1 for xls Excel support Use pip or conda to install xlrd.
ㄴ ModuleNotFoundError 모듈을 올린적이 없어서 발생되는 오류
# 해당 오류가 뜰때는 모두 라이브러리를 설치하지 않았을때 발생되는 오류
# Python 의 라이브러리는 pypi 에서 관리함
# (1) 설치시에 명령어는 pypi 에서 필요한 install 파일을 검색후 명령어를 복사하여 => cmd에서 실행
# (2) 해당 명령어를 주피터 노트북 자체에서 실행할수 있음 이때는 명령어를 ! pip install xlrd => ! 뒤에 붙여줘야함
! pip install xlrd
pd.read_excel('../data/population_in_Seoul.xls')
ㄴ install후 잘불러와지는것 확인
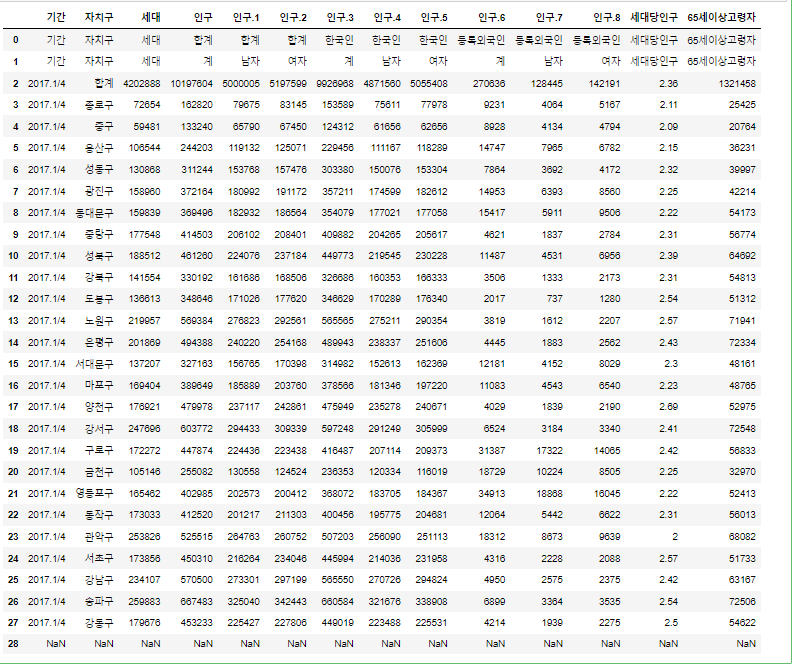
실습 4) population_in_Seoul.xls 파일을 읽으세요.
header 는 3번째 row 로 사용할 것입니다. 따라서 header = 2 로 셋팅하세요.
엑셀파일의 컬럼은 B, D, G, J, N 만 사용할 것입니다.
encoding='utf-8' 옵션을 넣습니다.
# 요청사항에 맞게 설정 후 pop_Seoul 이라는 변수로 메모리에 업로드
pop_Seoul = pd.read_excel('../data/population_in_Seoul.xls',
header=2,
usecols='B, D, G, J, N',)

실습 5-1) pop_Seoul 의 컬럼명을 모두 출력하세요.
pop_Seoul.columns
Index(['자치구', '계', '계.1', '계.2', '65세이상고령자'], dtype='object')실습 5-2) 컬럼명을 다음처럼 바꿉니다.
0번째는 '구별' , 1번째는 '인구수', 2번쨰는 '한국인', 3번째는 '외국인', 4번째는 '고령자' 로 rename
# pop_Seoul.rename(columns= { }, inplace=True) 를 사용 해도 되고,
# pandas는 그냥 위치에 맞게 그대로 적어주면 데이터에 바로 적용된다.
pop_Seoul.columns = [ '구별', '인구수', '한국인', '외국인' , '고령자']

실습 6) CCTV 갯수가 가장 많은 순부터 적은 순으로 정렬한 후, 상위 20개만 화면에 보여주세요.
# CCTV 갯수는 소계항목이므로 해당 항목으로 내림차순 정렬
CCTV_Seoul.sort_values('소계' , ascending=False).head(20)

실습 7) 최근 3년간 CCTV 증가율을 계산하여, dataframe 에 '최근증가율' 컬럼을 추가하세요.
증가율 계산 : (2016 + 2015 + 2014) / 2013이전 * 100
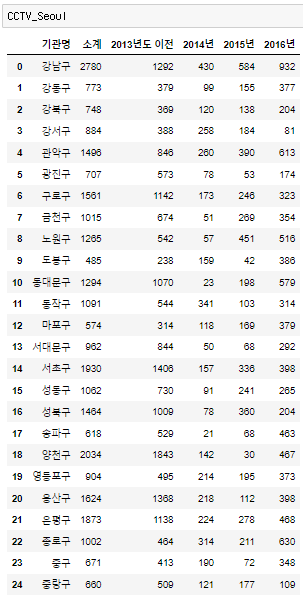
# 증가율 계산 : (2016 + 2015 + 2014) / 2013이전 * 100
CCTV_Seoul['최근증가율'] = ((CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전']) * 100
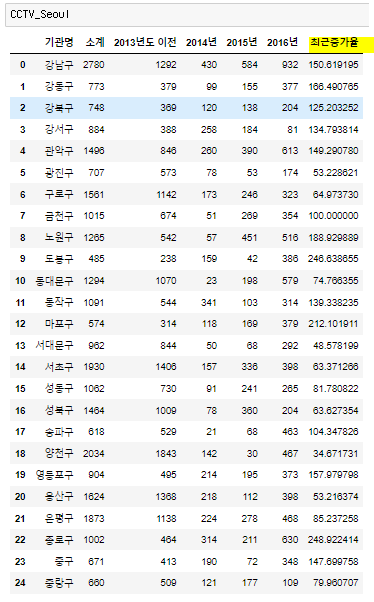
실습 8) 최근 3년간 CCTV 증가율이 가장 높은 순으로 5개의 구를 찾으세요.
CCTV_Seoul.sort_values('최근증가율' , ascending=False).head(5)

실습 9-1) 서울시의 인구 데이터 중, 가장 첫번째 행은 필요 없으니, 삭제하세요.
# 1번째 방법은 .drop 함수 사용
pop_Seoul.drop( 0 , axis= 0 , inplace=True)
# 2번째 방법은 첫행을 제외하고 가져오기 .loc 사용
pop_Seoul = pop_Seoul.loc[ 1 : , ]
pop_Seoul
# 둘중에 한가지 방법을 한번만 시행해야지 연속해서 할경우 계속 지워짐

실습 9-2) 서울시의 인구 데이터 중, NaN이 있는지 확인하고, NaN이 있으면 해당 row를 삭제하세요.
# 확인
pop_Seoul.isna()

# 삭제
pop_Seoul.dropna(inplace=True)
# 잘 삭제되었는지 확인
pop_Seoul.isna().sum()
자치구 0
계 0
계.1 0
계.2 0
65세이상고령자 0
dtype: int64
실습 10) '외국인비율' 과 '고령자비율' 두개의 컬럼을 추가하세요.
외국인비율 = 외국인 수 / 인구수 * 100
고령자비율 = 고령자 수 / 인구수 * 100

# 외국인비율 = 외국인 수 / 인구수 * 100
# 고령자비율 = 고령자 수 / 인구수 * 100
pop_Seoul['외국인비율'] = ( pop_Seoul['외국인'] / pop_Seoul['인구수'] ) * 100
pop_Seoul['고령자비율'] = ( pop_Seoul['고령자'] / pop_Seoul['인구수'] ) * 100
pop_Seoul

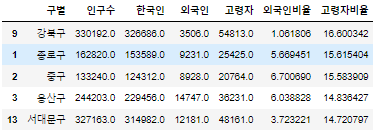
실습 11) 외국인 대상으로 장사를 하려 합니다. 외국인이 가장 많은 구와, 외국인비율이 가장 높은 구를 각각 5개씩 찾으세요.
pop_Seoul.sort_values('외국인' , ascending=False).head()

pop_Seoul.sort_values('외국인비율' , ascending=False).head()
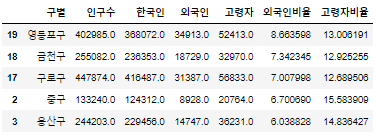
실습 12) 고령자 대상 마케팅을 구상 중입니다. 고령자가 가장 많은 구와, 고령자비율이 가장 높은 구를 각각 5개씩 찾으세요.
pop_Seoul.sort_values('고령자' , ascending=False).head()

pop_Seoul.sort_values('고령자비율' , ascending=False).head()
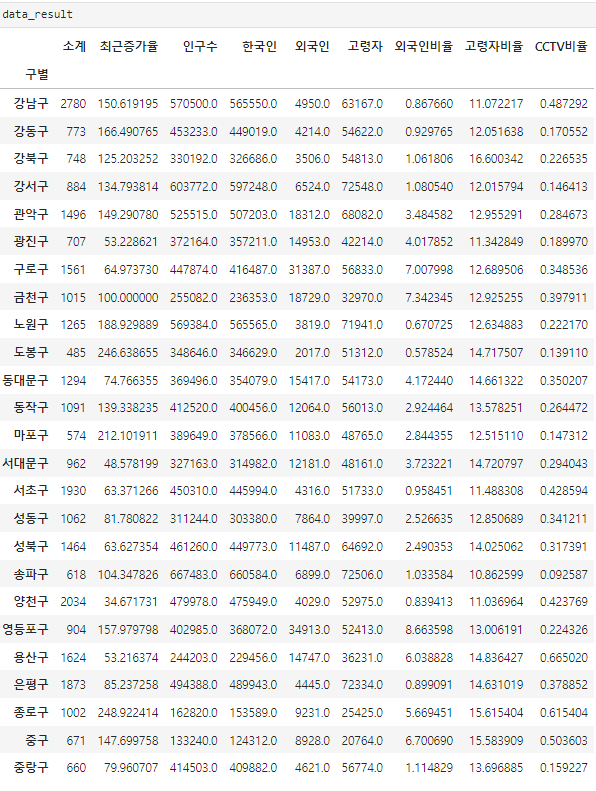
실습 13) CCTV 데이터와 인구 데이터 합치고 분석하기
data_result 라는 변수로 저장합니다.
# (1) pd.concat 사용 해당 데이터에 없는 부분은 모두 NaN으로 출력됨
# (2) merge()함수는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할때 사용한다.
# pd.merge(df_left, df_right, how='inner', on=None)이 default이다.
data_result = pd.merge(CCTV_Seoul, pop_Seoul , on='구별')
data_result

실습 14) data_result 에서, 다음 4개의 컬럼을 모두 버려 버립니다.
'2013년도 이전', 2014년', '2015년', '2016년'
data_result.drop(['2013년도 이전', '2014년', '2015년' , '2016년'] , axis=1 )

실습 15-1) dara_result 의 인덱스를, '구별' 로 바꿔 줍니다.
data_result = data_result.set_index('구별')
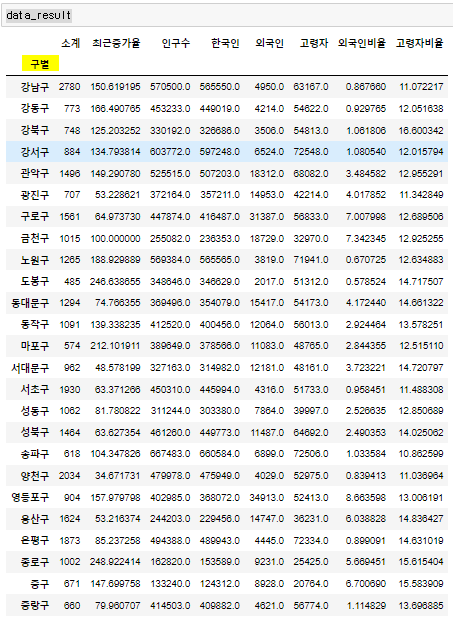
실습 15-2) 이 데이터프레임을 csv 파일로 저장합니다.
파일명은, CCTV_result.csv 입니다.
data_result.to_csv('CCTV_result.csv')
ㄴ jupyter notebook 실행한 가상환경 경로 폴더내에 파일 생성 확인
# 다시 불러와보자
data_result = pd.read_csv('../데이터분석2/CCTV_result.csv')
data_result

실습 16) 상관 관계 분석에 대해서 알아봅니다.
https://ko.wikipedia.org/wiki/%EC%83%81%EA%B4%80_%EB%B6%84%EC%84%9D
상관계수는 -1부터 1까지의 값을 갖는다.
1일 때 완벽한 양의 상관관계가 되고,
-1일 때 완벽한 음의 상관관계가 된다.
0이라면 별다른 상관관계가 없음을 의미한다.
# 상관 관계를 확인 .corr() -1 ~ 0 반비례 관계 0 ~ 1 비례 관계 -1 ~ 1 사이 수치로 출력된다.
data_result[['소계','고령자비율']].corr()

ㄴ - 인걸로 보아 반비례 관계임을 알수있다.
실습 17) CCTV의 갯수와 고령자 비율의 상관관계를 분석하세요
# 차트로 그려서 이미지로 확인해볼수있다.
# 스케터 활용
plt.scatter(data= data_result, x= '소계' , y= '고령자비율')
plt.xlabel('소계')
plt.ylabel('고령자비율')
plt.show()
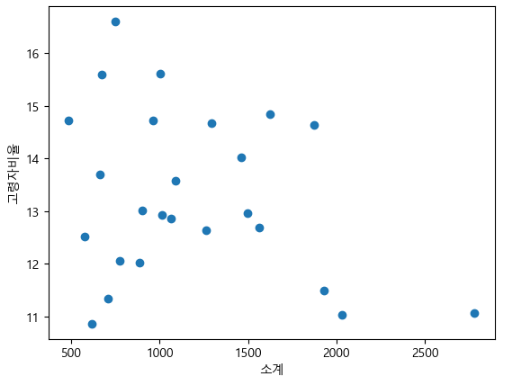
# 시본을 활용
sb.regplot(data= data_result, x= '소계' , y= '고령자비율')
plt.xlabel('소계')
plt.ylabel('고령자비율')
plt.show()

실습 18) CCTV의 갯수와 외국인 비율의 상관관계를 분석하세요.
# .corr() 으로 상관관계 확인
data_result[['소계','외국인비율']].corr()
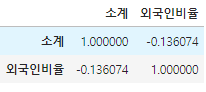
# 시각화는 시본을 활용
sb.regplot(data= data_result, x= '소계' , y= '외국인비율')
plt.xlabel('소계')
plt.ylabel('외국인비율')
plt.show()

실습 19) CCTV의 갯수와 인구수의 상관관계를 분석하세요.
data_result[['소계','인구수']].corr()

# 시본 활용
sb.regplot(data= data_result, x= '소계' , y= '인구수')
plt.xlabel('소계')
plt.ylabel('인구수')
plt.show()
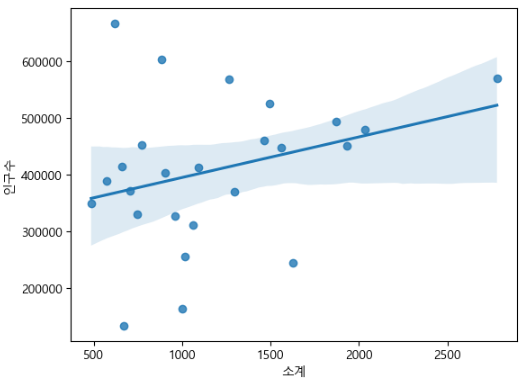
실습 20) 각 구의 CCTV의 갯수를 bar로 나타내세요.
pandas dataframe.plot 함수 사용
data_result.plot()
plt.show()

data_result['소계'].plot(kind = 'bar')
plt.show()
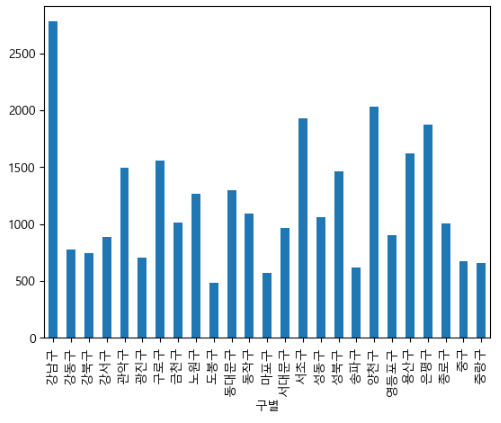
실습 21) 각 구의 CCTV의 갯수를, 먼저 소팅(큰순)한 후, bar로 나타내세요.
data_result['소계'].sort_values(ascending=False).plot(kind='bar')
plt.show()

# 각 구별 외국인 비율과 고령자 비율을 바차트로 나타내세요
data_result[['외국인비율','고령자비율']].plot(kind = 'bar')
plt.show()
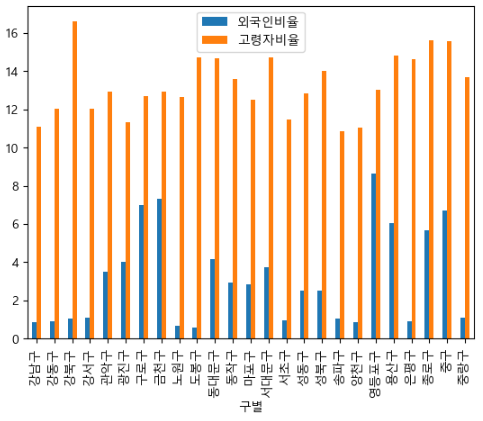
실습 22) 인구 한명당 CCTV의 비율을 계산하고,
이를 각 구별로 CCTV비율이 얼마인지 bar로 나타내세요.
data_result['CCTV비율'] = (data_result['소계'] / data_result['인구수']) * 100
data_result['CCTV비율'].sort_values(ascending=False).plot(kind='bar')
plt.show()

# 차트를 눕히고 싶으면 kind='bar' 뒤에 h 한글자 붙여주면 된다.
data_result['CCTV비율'].sort_values(ascending=False).plot(kind='barh')
plt.show()

다음 프로젝트 연습문제로 계속
'PYTHON LIBRARY > Project 연습 (새로운 개념 정리 추가!)' 카테고리의 다른 글
| 프로젝트(범죄현황) 연습(2) : Pandas pivot_table 익혀서 범죄 데이터에 적용 및 데이터 시각화 (0) | 2024.05.03 |
|---|---|
| 프로젝트(범죄현황) 연습(1) : 데이터 주무르기, API 키 생성 활용(googlemaps.Client()) (3) | 2024.04.18 |
| 프로젝트(대중교통) 연습 : 데이터를 분석하여 파이차트 그리기 plt.pie() (0) | 2024.04.17 |
| 프로젝트(기온데이터분석) 연습 : 데이터 가공하여 히스토그램, 산점도 그리기 plt.hist() , plt.scatter() (0) | 2024.04.16 |