반응형

< Convolution >
improving Computer Vision Accuracy using Convolutions
지금까지 Deep Neural Network (DNN) 를 이용해서 패션 mnist 를 분류했다.
정확도가, 트레이닝셋은 89% 정도이고 테스트셋으로는 87% 정도가 나왔다.
이제 Convolutional Neural Networks 이용해서 정확도를 향상시켜본다.
# 텐서플로우
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# 텐서플로우 트레인 테스트 파일 저장 방식
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()

X_train.shape
(60000, 28, 28)
# 3차원 데이터 불러오는 형식
X_train[ 0 , : , :]

# 정답지
y_train
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
# 이미지 데이터를 피쳐 스케일링 할때는 / 255.0
X_train = X_train / 255.0
X_test = X_test / 255.0
X_train.shape
(60000, 28, 28)
# 칼라 이미지이든 그레이스케일 이미지든 전부 처리할수 있는 인공지는 개발을 위해
# 4차원으로 reshape 한다.
# 왜냐하면 칼라 이미지는 4차원이기 때문에
X_train = X_train.reshape(60000, 28, 28, 1)
X_train.ndim
4
# X_test도 똑같이
X_test.shape
(10000, 28, 28)
X_test = X_test.reshape(10000, 28, 28, 1)
X_test.ndim
4
# 모델링
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 함수에 필터를 만들어줘야 한다. filters
# 이런 모델 구조를 CNN 이라 부른다.
from typing import Sequence
def build_model() :
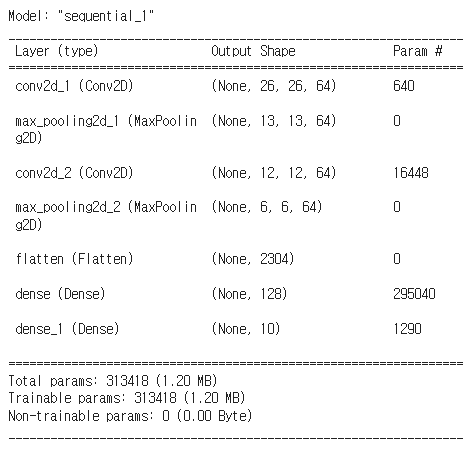
model = Sequential()
model.add( Conv2D(filters=64, kernel_size=(3,3), activation='relu', input_shape=(28,28,1)) )
model.add( MaxPooling2D(pool_size=(2,2) , strides=2 ) )
model.add( Conv2D(filters=64, kernel_size=(2,2), activation='relu') )
model.add( MaxPooling2D(pool_size=(2,2) , strides=2 ) )
model.add( Flatten() )
model.add( Dense(128, 'relu') )
model.add( Dense(10, 'softmax'))
model.compile(optimizer='adam', loss= 'sparse_categorical_crossentropy', metrics=['accuracy'])
return model
model = build_model()
model.summary()
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=10)
epoch_history = model.fit(X_train, y_train, epochs=1000, validation_split=0.2, callbacks=[early_stopping])

ㄴ 24회에 종료됨
# 시각화 해보자
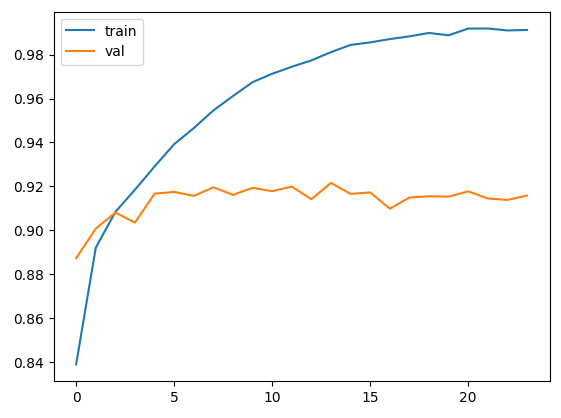
import matplotlib.pyplot as plt
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.legend(['train', 'val'])
plt.show()
model.evaluate(X_test, y_test)
313/313 [==============================] - 1s 3ms/step - loss: 0.5892 - accuracy: 0.9113
[0.5891915559768677, 0.911300003528595]
from sklearn.metrics import confusion_matrix
y_test
array([9, 2, 1, ..., 8, 1, 5], dtype=uint8)y_pred = model.predict(X_test)
313/313 [==============================] - 1s 2ms/step
y_pred = y_pred.argmax(axis=1)
y_pred
array([9, 2, 1, ..., 8, 1, 5])
confusion_matrix(y_test, y_pred)
array([[837, 0, 7, 19, 3, 2, 127, 0, 4, 1],
[ 2, 978, 1, 10, 4, 0, 4, 0, 1, 0],
[ 17, 0, 850, 7, 48, 0, 78, 0, 0, 0],
[ 19, 4, 10, 904, 20, 0, 41, 0, 1, 1],
[ 1, 0, 45, 24, 851, 0, 79, 0, 0, 0],
[ 1, 0, 0, 0, 0, 971, 0, 20, 1, 7],
[ 89, 2, 42, 22, 41, 1, 799, 0, 4, 0],
[ 0, 0, 0, 0, 0, 8, 0, 981, 0, 11],
[ 7, 0, 1, 1, 2, 1, 4, 3, 981, 0],
[ 0, 0, 1, 0, 0, 3, 0, 35, 0, 961]])
트레이닝셋은 93% , 테스트셋은 91% 까지 나온다.
에포크를 20까지 해보면, 트레이닝셋 정확도는 올라가지만 밸리데이션 정확도는 내려간다. 즉, 오버핏팅이 된다.
다음게시글로 계속
728x90
반응형
'DEEP LEARNING > Deep Learning Library' 카테고리의 다른 글
| DL(딥러닝) : Augmentation로 학습된 AI Transfer Learning & Fine Tunning (2) | 2024.05.01 |
|---|---|
| DL(딥러닝) : 데이터 증강 (Augmentation) 학습 (0) | 2024.04.30 |
| DL(딥러닝) : Tensflow의 Fashion-MNIST 활용(DNN) (2) (0) | 2024.04.30 |
| DL(딥러닝) : Tensflow의 Fashion-MNIST 활용(DNN) (1) (0) | 2024.04.30 |
| Deep Learning 개념 정리 (0) | 2024.04.16 |