반응형

< 자동차 연비 예측 >
# Auto MPG 데이터셋을 사용하여 1970년대 후반과 1980년대 초반의 자동차 연비를 예측하는 모델을 만듭니다.
# 이 정보에는 실린더 수, 배기량, 마력(horsepower), 공차 중량 같은 속성이 포함됩니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 구글 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
# Working Directory 설정
# 파일은 auto-mpg.csv 입니다.
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ML2/data/auto-mpg.csv')
df
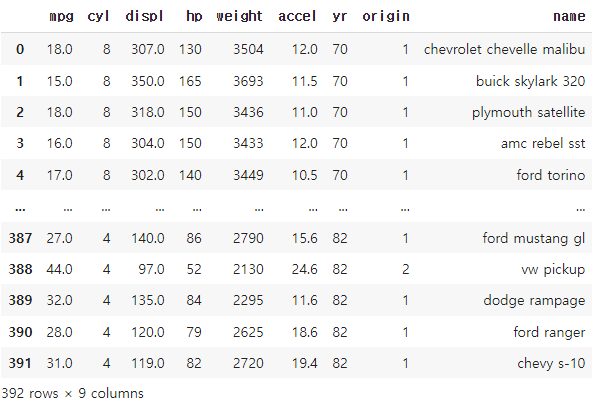
# 1 빈데이터 확인
df.isna().sum()
mpg 0
cyl 0
displ 0
hp 0
weight 0
accel 0
yr 0
origin 0
name 0
dtype: int64
# 2 빈 데이터 삭제
# 없으므로 패스
# 만약있다면
# df.dropna(inplace=True)
# 3. X , y 셋팅
df.describe()

ㄴ 데이터 통계치를 분석하여 X,y로 설정할 데이터 분류하기
y = df['mpg']
y
0 18.0
1 15.0
2 18.0
3 16.0
4 17.0
...
387 27.0
388 44.0
389 32.0
390 28.0
391 31.0
Name: mpg, Length: 392, dtype: float64
X = df.loc[ : ,'cyl':'origin']
X
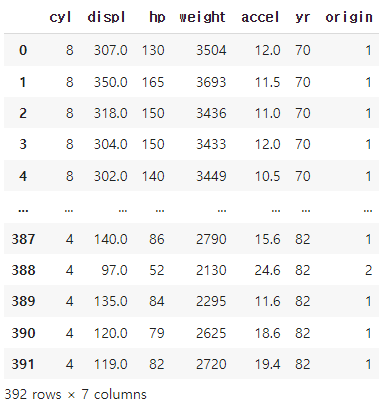
# 4. 카테고리컬 데이터 처리
# Origin 컬럼은 다음과 같다. (1. American, 2. European,3. Japanese)
# prompt: X['origin'] 컬럼을 columtransformer로 원핫 인코딩 해줘
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer([('encoding', OneHotEncoder(), [6])],remainder='passthrough')
X = ct.fit_transform(X)
X
array([[1.000e+00, 0.000e+00, 0.000e+00, ..., 3.504e+03, 1.200e+01,
7.000e+01],
[1.000e+00, 0.000e+00, 0.000e+00, ..., 3.693e+03, 1.150e+01,
7.000e+01],
[1.000e+00, 0.000e+00, 0.000e+00, ..., 3.436e+03, 1.100e+01,
7.000e+01],
...,
[1.000e+00, 0.000e+00, 0.000e+00, ..., 2.295e+03, 1.160e+01,
8.200e+01],
[1.000e+00, 0.000e+00, 0.000e+00, ..., 2.625e+03, 1.860e+01,
8.200e+01],
[1.000e+00, 0.000e+00, 0.000e+00, ..., 2.720e+03, 1.940e+01,
8.200e+01]])
# 좌측열 삭제
X = pd.DataFrame(X).drop(0, axis=1).values
X
array([[ 0. , 0. , 8. , ..., 3504. , 12. , 70. ],
[ 0. , 0. , 8. , ..., 3693. , 11.5, 70. ],
[ 0. , 0. , 8. , ..., 3436. , 11. , 70. ],
...,
[ 0. , 0. , 4. , ..., 2295. , 11.6, 82. ],
[ 0. , 0. , 4. , ..., 2625. , 18.6, 82. ],
[ 0. , 0. , 4. , ..., 2720. , 19.4, 82. ]])
# 5. X 만 피처 스케일링 하시오 (차트 확인을 위해, y는 하지 않습니다.)
from sklearn.preprocessing import StandardScaler
scaler_X = StandardScaler()
X = scaler_X.fit_transform(X)
X
array([[-0.45812285, -0.50239045, 1.48394702, ..., 0.62054034,
-1.285258 , -1.62531533],
[-0.45812285, -0.50239045, 1.48394702, ..., 0.84333403,
-1.46672362, -1.62531533],
[-0.45812285, -0.50239045, 1.48394702, ..., 0.54038176,
-1.64818924, -1.62531533],
...,
[-0.45812285, -0.50239045, -0.86401356, ..., -0.80463202,
-1.4304305 , 1.63640964],
[-0.45812285, -0.50239045, -0.86401356, ..., -0.41562716,
1.11008813, 1.63640964],
[-0.45812285, -0.50239045, -0.86401356, ..., -0.30364091,
1.40043312, 1.63640964]])
# 그냥 y도 진행하자.
y
0 18.0
1 15.0
2 18.0
3 16.0
4 17.0
...
387 27.0
388 44.0
389 32.0
390 28.0
391 31.0
Name: mpg, Length: 392, dtype: float64# prompt: y 용 스탠다드스케일러 만들어줘
scaler_y = StandardScaler()
y = scaler_y.fit_transform(y.values.reshape(-1,1))
y
array([[-0.69863841],
[-1.08349824],
[-0.69863841],
[-0.95521163],
[-0.82692502],
[-1.08349824],
[-1.21178485],
[-1.21178485],
[-1.21178485],
[-1.08349824],
[-1.08349824],
[-1.21178485],
[-1.08349824],
[-1.21178485],
[ 0.07108125],
[-0.18549197],ㄴ y도 392개 출력
# 5. 트레인 / 테스트용 셋으로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 딥러닝 모델링
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def build_model():
model = Sequential()
model.add(Dense(64,'relu', input_shape=(X_train.shape[1], )))
model.add(Dense(64,'relu'))
model.add(Dense(1,'linear'))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001) , loss='mse', metrics=['mae'])
return model
model = build_model()
## epoch_history 객체에 저장된 통계치를 사용해 모델의 훈련 과정을 시각화!
# epochs 순서가 많아서 loss값이 작아진다고 무조건 똑똑한 인공지능이 아니다.
# 이미 사전에 주입한 데이터만 분석한것이므로 과거만 잘 맞추는 인공지능이 될수있다.
# 그래서 새로운 데이터 주입전에 모의고사를 보듯이 자체 평가를 해볼수 있게 파라미터를 추가해줬다 validation_split=
epoch_history = model.fit(X_train, y_train, epochs =500, validation_split=0.2)

### Validation ###
# 벨리데이션이란, 에포크가 한번 끝날때 마다, 학습에 사용하지 않는 데이터로 시험을 보는것을 말한다.
# 테스트란? 인공지능 학습이 완전히 다 끝났을때 평가하는것을 테스트라고 하고 (학습이 다끝나고 보는 수능)
# 밸리데이션이란? 에포크가 끝날때마다 평가하는것을 말한다. (매달 보는 모의 고사)
# 변수명뒤에 .history 를 붙이는 이유는 history가 객체의 속성이기 때문이다.
# fit() 메서드는 훈련이 완료된 후에 history 객체를 반환하는데, 이 객체는 훈련 과정에서 계산된 손실, 메트릭 등의 값들을 저장하고 있다.
# 이 값에 접근하기 위해서는 .history라는 속성을 사용하는데 변수명이 abc일 경우 abc.history.keys() 등으로 입력하면 된다.
epoch_history.history.keys()
dict_keys(['loss', 'mae', 'val_loss', 'val_mae'])
epoch_history.history['loss']
[0.010365895926952362,
0.009198378771543503,
0.009776923805475235,
0.00917946919798851,
0.009567590430378914,
0.009651419706642628,
0.013823172077536583,
0.012408467009663582,
0.011881113052368164,
0.011096143163740635,
0.012852894142270088,
0.01186368428170681, 0.0007680894923396409,
0.000697538023814559,
0.0008371960138902068,
0.0007717445841990411,
0.0012455773539841175,
0.0011748876422643661,
0.001389685901813209,
0.0011413138126954436,
0.0023559799883514643,
0.0015253833262249827,
0.0017067514127120376,
0.0018012000946328044,
0.001573091489262879,
0.0011422329116612673,
0.0012794890208169818,
0.0013460105983540416,
0.0013429141836240888,
0.0018032165244221687]
epoch_history.history['val_loss']
[0.17273388803005219,
0.16186785697937012,
0.1689145267009735,
0.16389547288417816,
0.16136114299297333,
0.16801871359348297,
0.1941702961921692,
0.1671251505613327,
0.1629466712474823,
0.1540384739637375,
0.1570701003074646,
0.18386848270893097,
0.17231059074401855,
0.15743085741996765,
0.15930859744548798,
0.18305155634880066,
0.1602407991886139, 0.1830773800611496,
0.1899656504392624,
0.18058843910694122,
0.1792326718568802,
0.17603695392608643,
0.1836589276790619,
0.18174855411052704,
0.17834721505641937,
0.18306955695152283,
0.1868133842945099,
0.18038366734981537,
0.18509803712368011,
0.18960610032081604,
0.1855134516954422,
0.18240995705127716]
plt.plot(epoch_history.history['loss'])
plt.show()

plt.plot(epoch_history.history['val_loss'])
plt.show()

# 두개를 합쳐서 보자.
plt.plot(epoch_history.history['loss'])
plt.plot(epoch_history.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.savefig('loss.jpg')
plt.show()

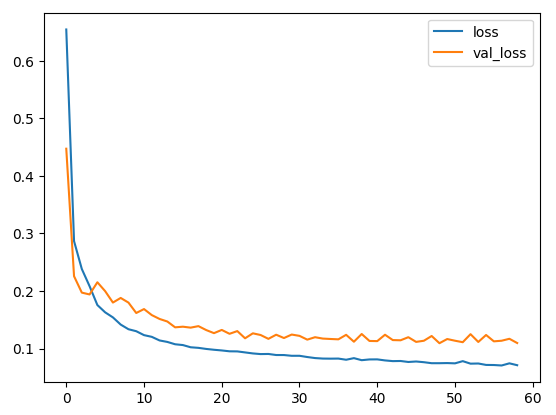
# 이 그래프를 보면 수 백번 에포크를 진행한 이후에는 모델이 거의 향상되지 않는 것 같습니다. model.fit 메서드를 수정하여 검증 점수가 향상되지 않으면 자동으로 훈련을 멈추도록 만들어 보죠.
# 에포크마다 훈련 상태를 점검하기 위해 EarlyStopping 콜백(callback)을 사용하겠습니다.
# 지정된 에포크 횟수 동안 성능 향상이 없으면 자동으로 훈련이 멈춥니다.
# Google Colab에서 자동완성 안되면 Ctrl + space 누르면 출력됨
model = build_model()
# callback 이란?? 내가 만든 함수를, 프레임워크가 특정 시점에 실행시켜주는것!
# patience 를 5로 설정하면, 5번의 에포크동안 성능향상이 없으면, 학습을 멈추라고 지정하는것!
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
epoch_history = model.fit(X_train, y_train, epochs =100000, validation_split=0.2, callbacks= [early_stop])


ㄴ 59번째에서 종료
plt.plot(epoch_history.history['loss'])
plt.plot(epoch_history.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.savefig('loss.jpg')
plt.show()
# 최종시험
model.evaluate(X_test, y_test)
3/3 [==============================] - 0s 8ms/step - loss: 0.1192 - mae: 0.2535
[0.11922302842140198, 0.25354114174842834]다음 게시글로 계속
728x90
반응형
'DEEP LEARNING > Deep Learning Project' 카테고리의 다른 글
| DL(딥러닝) 실습 : Prophet을 활용한 테슬라 주가 분석 (1) | 2024.05.02 |
|---|---|
| DL(딥러닝) 실습 : Prophet을 활용하여 시카고 범죄율을 예측해 보자 (0) | 2024.05.02 |
| DL(딥러닝) 실습 : keras.models Sequential/.layers Dense 활용한 차량 구매금액 예측 (0) | 2024.04.30 |
| DL(딥러닝) 실습 : Tensorflow의 keras를 활용한 ANN Deep Learning (2) | 2024.04.30 |