
< Neural Networks and Deep Learning >
# 금융상품 갱신 여부 예측하는 ANN
# Churn_Modelling.csv 파일을 보면, 고객 정보와 해당 고객이 금융상품을 갱신했는지 안했는지의 여부에 대한 데이터가 있다.
# 이 데이터를 가지고 갱신여부를 예측하는 딥러닝을 구성하시오.
# 실습은 구글 Colab을 사용하여 진행한다.
# 데이터 불러오는 방법은 이전장에서 설명했던 방법중 내 구글 드라이브에 csv 파일을 갖다놓고, 코랩을 연경실키는 방법을 사용.
RowNumber 0
CustomerId 0
Surname 0
CreditScore 0
Geography 0
Gender 0
Age 0
Tenure 0
Balance 0
NumOfProducts 0
HasCrCard 0
IsActiveMember 0
EstimatedSalary 0
Exited 0
dtype: int64
# y는 Exited 컬럼을 X 는'CreditScore':'EstimatedSalary'컬럼 까지 지정
# 데이터에 문자열이 포함되어 있으므로 인코딩을 진행해야 한다.
# 코랩에서는 인공지능을 활용하여 코딩할수도 있다!
# 생성 키를 누르면 하단에 원하는 코드를 말하면 자동적으로 코드를 생성해준다.
# but, 무조건 정답이 아니므로 정확한 명령어를 인식하고 있어야 하고, 완성해준 코드도 본인이 직접 검토할줄 알아야 한다.
Geography
France 5014
Germany 2509
Spain 2477
Name: count, dtype: int6432# 원핫 인코딩 진행
['France', 'Germany', 'Spain']0 France
1 Spain
2 France
3 France
4 Spain
...
9995 France
9996 France
9997 France
9998 Germany
9999 France
Name: Geography, Length: 10000, dtype: objectarray([[1.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 1.0000000e+00,
1.0000000e+00, 1.0134888e+05],
[0.0000000e+00, 0.0000000e+00, 1.0000000e+00, ..., 0.0000000e+00,
1.0000000e+00, 1.1254258e+05],
[1.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 1.0000000e+00,
0.0000000e+00, 1.1393157e+05],
...,
[1.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 0.0000000e+00,
1.0000000e+00, 4.2085580e+04],
[0.0000000e+00, 1.0000000e+00, 0.0000000e+00, ..., 1.0000000e+00,
0.0000000e+00, 9.2888520e+04],
[1.0000000e+00, 0.0000000e+00, 0.0000000e+00, ..., 1.0000000e+00,
0.0000000e+00, 3.8190780e+04]])array([[0.0000000e+00, 0.0000000e+00, 6.1900000e+02, ..., 1.0000000e+00,
1.0000000e+00, 1.0134888e+05],
[0.0000000e+00, 1.0000000e+00, 6.0800000e+02, ..., 0.0000000e+00,
1.0000000e+00, 1.1254258e+05],
[0.0000000e+00, 0.0000000e+00, 5.0200000e+02, ..., 1.0000000e+00,
0.0000000e+00, 1.1393157e+05],
...,
[0.0000000e+00, 0.0000000e+00, 7.0900000e+02, ..., 0.0000000e+00,
1.0000000e+00, 4.2085580e+04],
[1.0000000e+00, 0.0000000e+00, 7.7200000e+02, ..., 1.0000000e+00,
0.0000000e+00, 9.2888520e+04],
[0.0000000e+00, 0.0000000e+00, 7.9200000e+02, ..., 1.0000000e+00,
0.0000000e+00, 3.8190780e+04]])
# 이제 가공한 데이터를 학습, 예측을 위하여 피쳐 스케일링 진행
array([[-0.57873591, -0.57380915, -0.32622142, ..., 0.64609167,
0.97024255, 0.02188649],
[-0.57873591, 1.74273971, -0.44003595, ..., -1.54776799,
0.97024255, 0.21653375],
[-0.57873591, -0.57380915, -1.53679418, ..., 0.64609167,
-1.03067011, 0.2406869 ],
...,
[-0.57873591, -0.57380915, 0.60498839, ..., -1.54776799,
0.97024255, -1.00864308],
[ 1.72790383, -0.57380915, 1.25683526, ..., 0.64609167,
-1.03067011, -0.12523071],
[-0.57873591, -0.57380915, 1.46377078, ..., 0.64609167,
-1.03067011, -1.07636976]])0 1
1 0
2 1
3 0
4 0
..
9995 0
9996 0
9997 1
9998 1
9999 0
Name: Exited, Length: 10000, dtype: int64
# 이제 학습,예측을 위한 데이터 프리프로세싱이 모두 완료되었다!!
# 이제 인공지능을 만들고 학습, 예측을 진행해보자.
# 학습전 데이터개수 한번더 검토
(10000, 11)array([-0.57873591, -0.57380915, -0.32622142, -1.09598752, 0.29351742,
-1.04175968, -1.22584767, -0.91158349, 0.64609167, 0.97024255,
0.02188649])
/usr/local/lib/python3.10/dist-packages/keras/src/layers/core/dense.py:86: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead. super().__init__(activity_regularizer=activity_regularizer, **kwargs)
Model: "sequential"

Epoch 1/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 8s 5ms/step - accuracy: 0.7925 - loss: 0.5189
Epoch 2/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 4s 5ms/step - accuracy: 0.8145 - loss: 0.4285
Epoch 3/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 3s 4ms/step - accuracy: 0.8126 - loss: 0.4292
Epoch 4/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 4s 3ms/step - accuracy: 0.8322 - loss: 0.4015
Epoch 5/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.8432 - loss: 0.3831
Epoch 6/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.8404 - loss: 0.3815
Epoch 7/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 3ms/step - accuracy: 0.8482 - loss: 0.3571
Epoch 8/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.8503 - loss: 0.3632
Epoch 9/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 1ms/step - accuracy: 0.8526 - loss: 0.3515
Epoch 10/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8624 - loss: 0.3375
Epoch 11/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8500 - loss: 0.3588
Epoch 12/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8620 - loss: 0.3410
Epoch 13/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8558 - loss: 0.3422
Epoch 14/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8644 - loss: 0.3317
Epoch 15/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8589 - loss: 0.3455
Epoch 16/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8587 - loss: 0.3477
Epoch 17/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step - accuracy: 0.8664 - loss: 0.3338
Epoch 18/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8603 - loss: 0.3430
Epoch 19/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 2s 1ms/step - accuracy: 0.8622 - loss: 0.3349
Epoch 20/20
800/800 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.8635 - loss: 0.3352
<keras.src.callbacks.history.History at 0x78163b9ea0e0>63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8576 - loss: 0.3323
[0.3400079309940338, 0.859000027179718]63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
array([[0.25733587],
[0.33500573],
[0.13444375],
...,
[0.14407456],
[0.15712005],
[0.14735286]], dtype=float32)
9394 0
898 1
2398 0
5906 0
2343 0
..
1037 0
2899 0
9549 0
2740 0
6690 0
Name: Exited, Length: 2000, dtype: int64
2000
array([[1525, 70],
[ 212, 193]])
1.0805
0.859
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8576 - loss: 0.3323
[0.3400079309940338, 0.859000027179718]

array([[ 0.15510868, 0.48057753, 0.12048828, -0.11949058, 0.21905184,
-0.21320768, -0.36722365, 0.20958157],
[ 0.03201314, 0.0164311 , 0.25372922, 0.18349856, 0.4126134 ,
-0.19020617, -0.46901786, 0.12217822],
[-0.01604781, 0.0390755 , 0.07829322, 0.15240642, -0.062962 ,
0.33552325, -0.04676249, 0.14250895],
[-0.01489559, 0.10695752, -0.06455339, 0.07174824, -0.37085876,
-0.3773975 , 0.2848377 , 0.25782293],
[ 0.24178272, 0.16687939, 0.31543192, 0.7522099 , -0.62823325,
-0.33388972, -0.6350836 , -0.44254327],
[-0.05174403, 0.02457642, -0.02072264, 0.09515063, 0.07687005,
-0.18021777, 0.03759337, -0.05291931],
[-0.30960017, -0.79405934, 0.0745323 , -0.46475443, 0.107397 ,
0.13863975, -0.42826137, -0.26842293],
[-1.452625 , -0.8741043 , 0.9447404 , -0.28960004, -0.3195589 ,
-0.35342467, -0.35981154, 0.04665589],
[ 0.09442655, -0.1937058 , 0.11555907, 0.24578622, 0.11271417,
0.110532 , -0.30035266, 0.12412481],
[-0.5818811 , 0.00982098, -0.52750164, 0.4784998 , -0.52636874,
-0.5272814 , 0.21656933, -0.49670872],
[ 0.05266256, 0.0443663 , 0.07713059, -0.18322042, 0.04967958,
-0.6340016 , -0.21295096, 0.18633987]], dtype=float32)
array([ 0.06635607, -0.02907321, -0.16964573, 0.33312395, 0.23244065,
0.4578039 , 0.52377367, 1.0142717 ], dtype=float32)
array([[ 0.2001995 , -0.6377279 , 0.6321338 , -0.63409925, -0.13164514,
-0.231192 ],
[-0.6715094 , -0.0855982 , 0.57218874, 0.32056037, -0.33826792,
-0.80573475],
[ 0.78518236, -0.27362934, 0.76037705, 0.10874667, -0.3069774 ,
0.38885775],
[-0.37846598, 0.6472185 , -0.04943345, 0.5838219 , -0.44037664,
0.21265864],
[-0.46858358, 0.15887392, -0.4912556 , -0.22084698, -0.16053215,
-0.6083974 ],
[-0.5674717 , -0.45886916, 0.25360072, -0.09564873, 0.37213144,
-0.02956283],
[ 0.1892614 , -0.42350322, -0.08122479, 0.07863261, 0.6747974 ,
-0.02157269],
[ 0.14546366, 0.39898443, 0.12616812, 0.63126457, 0.6642552 ,
-0.34389728]], dtype=float32)
[array([[ 1.3704257 ],
[-1.0855359 ],
[ 1.0281827 ],
[-0.56768525],
[-1.1445732 ],
[ 0.6428316 ]], dtype=float32),
array([-0.2651697], dtype=float32)]
< 다음 신규 데이터를 통해 분류해 보자 >
- Geography: France
- Credit Score: 600
- Gender: Male
- Age: 40
- Tenure: 3
- Balance: 60000
- Number of Products: 2
- Has Credit Card: Yes
- Is Active Member: Yes
- Estimated Salary: 50000
[[600, 'France', 'Male', 40, 3, 60000, 2, 1, 1, 50000]]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1 entries, 0 to 0
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 1 non-null int64
1 1 1 non-null object
2 2 1 non-null object
3 3 1 non-null int64
4 4 1 non-null int64
5 5 1 non-null int64
6 6 1 non-null int64
7 7 1 non-null int64
8 8 1 non-null int64
9 9 1 non-null int64
dtypes: int64(8), object(2)
memory usage: 208.0+ bytes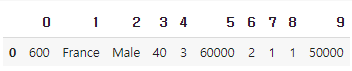
Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography',
'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard',
'IsActiveMember', 'EstimatedSalary', 'Exited'],
dtype='object')

array([[0]])
array([[-0.57873591, -0.57380915, -0.52281016, 0.91241915, 0.10281024,
-0.69598177, -0.26422114, 0.80773656, 0.64609167, 0.97024255,
-0.87101922]])
1/1━━━━━━━━━━━━━━━━━━━━0s19ms/step
array([[0]])
< 용어 정리 >
# epoch
- 한 번의 epoch는 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
# batch_size
메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없습니다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size라고 합니다.
출처 : https://www.slideshare.net/w0ong/ss-82372826
텐서플로우로 배우는 딥러닝
텐서플로우로 배우는 딥러닝 - Download as a PDF or view online for free
www.slideshare.net
< GridSearch 를 이용한, 최적의 하이퍼 파라미터 찾기 >
# 학습에 시간이 오래 소요된다.

{'batch_size': 10, 'epochs': 30, 'optimizer': 'adam'}0.86
200/200 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step
array([0, 0, 0, ..., 0, 0, 0])
200/200 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step
array([[0.7249168 , 0.27508318],
[0.71621585, 0.28378415],
[0.8745559 , 0.12544413],
...,
[0.81129515, 0.18870485],
[0.8167985 , 0.18320148],
[0.8356137 , 0.16438629]], dtype=float32)
다음 게시글로 계속
'DEEP LEARNING > Deep Learning Project' 카테고리의 다른 글
| DL(딥러닝) 실습 : Prophet을 활용한 테슬라 주가 분석 (1) | 2024.05.02 |
|---|---|
| DL(딥러닝) 실습 : Prophet을 활용하여 시카고 범죄율을 예측해 보자 (0) | 2024.05.02 |
| DL(딥러닝) 실습 : validation_split 모델링 시각화 & EarlyStopping 콜백(callback) 사용 (자동차 연비 예측 ANN) (0) | 2024.04.30 |
| DL(딥러닝) 실습 : keras.models Sequential/.layers Dense 활용한 차량 구매금액 예측 (0) | 2024.04.30 |