
< 자동차 구매 가격 예측 >
# PROBLEM STATEMENT
# 다음과 같은 컬럼을 가지고 있는 데이터셋을 읽어서, 어떠한 고객이 있을때, 그 고객이 얼마정도의 차를 구매할 수 있을지를 예측하여, 그 사람에게 맞는 자동차를 보여주려 한다.
- Customer Name
- Customer e-mail
- Country
- Gender
- Age
- Annual Salary
- Credit Card Debt
- Net Worth (순자산)
# 예측하고자 하는 값 :
- Car Purchase Amount
STEP #0: 라이브러리 임포트 및 코랩 환경 설정
# csv 파일을 읽기 위해, 구글 드라이브 마운트 하시오
Mounted at /content/drive
STEP #1: IMPORT DATASET
# Car_Purchasing_Data.csv 파일을 사용한다. 코랩의 경우 구글드라이브의 전체경로를 복사하여 파일 읽는다.
# 인코딩은 다음처럼 한다. encoding='ISO-8859-1'
# 컬럼을 확인하고, 기본 통계 데이터를 확인해 보자

# 연봉이 가장 높은 사람은 누구인가

# 나이가 가장 어린 고객은, 연봉이 얼마인가
444 70467.29492
Name: Annual Salary, dtype: float64
STEP #2: VISUALIZE DATASET
# 상관관계를 분석하기 위해, pairplot 을 그려보자.
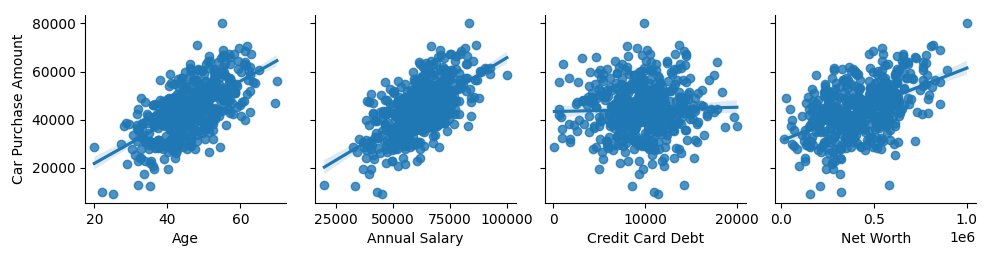
STEP #3: CREATE TESTING AND TRAINING DATASET/DATA CLEANING
# NaN 값이 있으면, 이를 해결하시오.
Customer Name 0
Customer e-mail 0
Country 0
Gender 0
Age 0
Annual Salary 0
Credit Card Debt 0
Net Worth 0
Car Purchase Amount 0
dtype: int64
# 학습을 위해 'Customer Name', 'Customer e-mail', 'Country', 'Car Purchase Amount' 컬럼을 제외한 컬럼만, X로 만드시오.

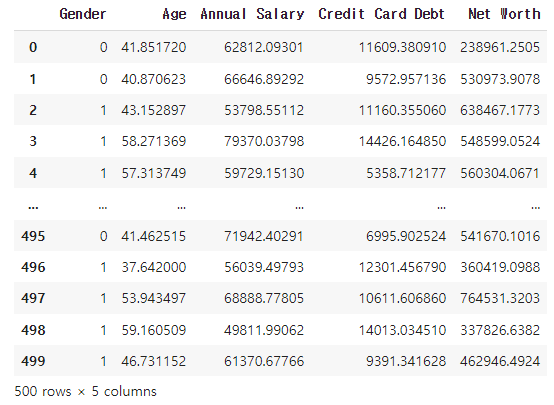
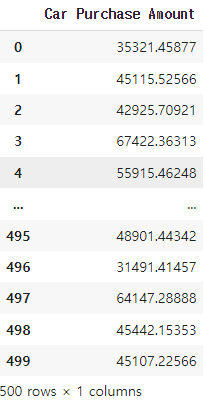
# y 값은 'Car Purchase Amount' 컬럼으로 셋팅하시오.
0 35321.45877
1 45115.52566
2 42925.70921
3 67422.36313
4 55915.46248
...
495 48901.44342
496 31491.41457
497 64147.28888
498 45442.15353
499 45107.22566
Name: Car Purchase Amount, Length: 500, dtype: float64
# 피처 스케일링 하겠습니다. 정규화(normalization)를 사용합니다. MinMaxScaler 를 이용하시오.
array([[0. , 0.4370344 , 0.53515116, 0.57836085, 0.22342985],
[0. , 0.41741247, 0.58308616, 0.476028 , 0.52140195],
[1. , 0.46305795, 0.42248189, 0.55579674, 0.63108896],
...,
[1. , 0.67886994, 0.61110973, 0.52822145, 0.75972584],
[1. , 0.78321017, 0.37264988, 0.69914746, 0.3243129 ],
[1. , 0.53462305, 0.51713347, 0.46690159, 0.45198622]])
# 학습을 위해서, y 의 shape 을 변경하시오.
(500,)
[33261.00057],
[41327.16554],
[49336.11628],
[51405.55229],
[31249.98803],
[43598.96993],
[48300.02057],
[54013.47595],
[38674.66038],
[37076.82508],
[37947.85125],
[41320.07256],
[66888.93694],
[12536.93842],
[39549.13039],
[52709.08196],
[53502.97742],
[52116.90791],
[38705.65839],
[48025.02542],
[59483.91183],
[35911.64559],
[41034.28343],
[51730.17434],
[53021.86074],
[32828.03477],
[29417.64694],
[57461.51158],
[50441.62427],
[41575.34739],
[46412.47781],ㄴ 500개 행이 전부 출력됨
# y 도 피처 스케일링 하겠습니다. X 처럼 y도 노멀라이징 하시오.
[0.6950749 ],
[0.49287831],
[0.12090943],
[0.50211776],
[0.80794216],
[0.62661214],
[0.43394857],
[0.60017103],
[0.42223485],
[0.01538345],
[0.37927499],
[0.64539707],
[0.51838974],
[0.45869677],
[0.26804521],
[0.2650104 ],
[0.84054134],
[0.84401542],
[0.35515157],
[0.406246 ],
[0.40680623],
[0.55963883],
[0.2561583 ],
[0.77096325],
[0.55305289],
[0.5264948 ],
[0.3236476 ],
[0.55070832],
[0.54057623],
[0.45669016],
[0.41053254],
[0.33433524],
[0.39926954],
[0.5420261 ],
[0.57366948],
[0.43793831],
[0.46897896],ㄴ 500개행 쭉 출력됨
STEP#4: TRAINING THE MODEL
# 트레이닝셋과 테스트셋으로 분리하시오. (테스트 사이즈는 25%로 하며, 동일 결과를 위해 랜덤스테이트는 50 으로 셋팅하시오.)
# 아래 라이브러리를 임포트 하시오
# 딥러닝을 이용한 모델링을 하시오.
옵티마이저는 'adam' 으로 하고, 로스펑션은 'mean_squared_error' 로 셋팅하여 컴파일 하시오

# 학습을 진행하시오.
Epoch 1/20
38/38 [==============================] - 1s 4ms/step - loss: 0.1310 - mse: 0.1310 - mae: 0.3061
Epoch 2/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0462 - mse: 0.0462 - mae: 0.1800
Epoch 3/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0223 - mse: 0.0223 - mae: 0.1197
Epoch 4/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0168 - mse: 0.0168 - mae: 0.1022
Epoch 5/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0144 - mse: 0.0144 - mae: 0.0942
Epoch 6/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0127 - mse: 0.0127 - mae: 0.0872
Epoch 7/20
38/38 [==============================] - 0s 5ms/step - loss: 0.0116 - mse: 0.0116 - mae: 0.0851
Epoch 8/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0105 - mse: 0.0105 - mae: 0.0809
Epoch 9/20
38/38 [==============================] - 0s 5ms/step - loss: 0.0095 - mse: 0.0095 - mae: 0.0776
Epoch 10/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0082 - mse: 0.0082 - mae: 0.0717
Epoch 11/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0071 - mse: 0.0071 - mae: 0.0671
Epoch 12/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0062 - mse: 0.0062 - mae: 0.0630
Epoch 13/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0054 - mse: 0.0054 - mae: 0.0584
Epoch 14/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0045 - mse: 0.0045 - mae: 0.0529
Epoch 15/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0041 - mse: 0.0041 - mae: 0.0501
Epoch 16/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0033 - mse: 0.0033 - mae: 0.0442
Epoch 17/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0028 - mse: 0.0028 - mae: 0.0404
Epoch 18/20
38/38 [==============================] - 0s 4ms/step - loss: 0.0024 - mse: 0.0024 - mae: 0.0360
Epoch 19/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0022 - mse: 0.0022 - mae: 0.0322
Epoch 20/20
38/38 [==============================] - 0s 3ms/step - loss: 0.0019 - mse: 0.0019 - mae: 0.0308
<keras.src.callbacks.History at 0x79ea48297dc0>
< STEP#5: EVALUATING THE MODEL >
# 테스트셋으로 예측을 해 보시오.
4/4 [==============================] - 0s 5ms/step - loss: 0.0025 - mse: 0.0025 - mae: 0.0337
[0.002524478593841195, 0.002524478593841195, 0.03370361030101776]
# MSE를 계산하시오
0.0025244786517285307
# 실제값과 예측값을 plot 으로 나타내시오.

< 신규 고객 데이터 예측 >
# 새로운 고객 데이터가 있습니다. 이 사람은 차량을 얼마정도 구매 가능한지 예측하시오.
# 여자이고, 나이는 38, 연봉은 90000, 카드빚은 2000, 순자산은 500000 일때,
# 어느정도의 차량을 구매할 수 있을지 예측하시오.
[{'Gender': 0,
'Age': 38,
'Annual Salary': 90000,
'Credit Card Debt': 2000,
'Net Worth': 500000}]

array([[0.09339616]], dtype=float32)
array([[15631.128]], dtype=float32)
다음 게시글로 계속
'DEEP LEARNING > Deep Learning Project' 카테고리의 다른 글
| DL(딥러닝) 실습 : Prophet을 활용한 테슬라 주가 분석 (1) | 2024.05.02 |
|---|---|
| DL(딥러닝) 실습 : Prophet을 활용하여 시카고 범죄율을 예측해 보자 (0) | 2024.05.02 |
| DL(딥러닝) 실습 : validation_split 모델링 시각화 & EarlyStopping 콜백(callback) 사용 (자동차 연비 예측 ANN) (0) | 2024.04.30 |
| DL(딥러닝) 실습 : Tensorflow의 keras를 활용한 ANN Deep Learning (2) | 2024.04.30 |