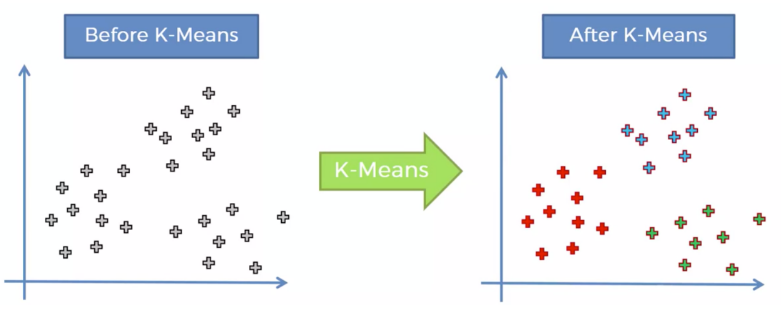
음식소비 데이터를 통해서 비슷한 고객으로 그룹핑 하자 > import numpy as npimport matplotlib.pyplot as pltimport pandas as pd df = pd.read_csv('../data/Cust_Spend_Data.csv') df.isna().sum()Cust_ID 0Name 0Avg_Mthly_Spend 0No_Of_Visits 0Apparel_Items 0FnV_Items 0Staples_Items 0dtype: int64 X = df.iloc[:,2:] import scipy.cluster.hierarchy as schimport matplotlib.pyplot a..