** 실습전 import 중요 **
import numpy as np
import random
# 데이터 전체에서 최대값, 최소값, 전체합, 전체평균, 표준편차, 중앙값을 구하세요
# 1부터 100 사이의 정수로 구성된 4행 5열 배열 생성
X = np.random.randint(1, 100+1, (4,5))
X
array([[74, 46, 91, 68, 83],
[29, 23, 66, 66, 86],
[93, 89, 71, 16, 64],
[ 4, 7, 84, 41, 4]])
# 최대값
X.max()
93
# 최소값
X.min()
4
# 모든 요소의 합계
X.sum()
1105
# 모든 요소의 평균값
X.mean()
55.25
# 표준 편차
X.std()
30.49077729412617
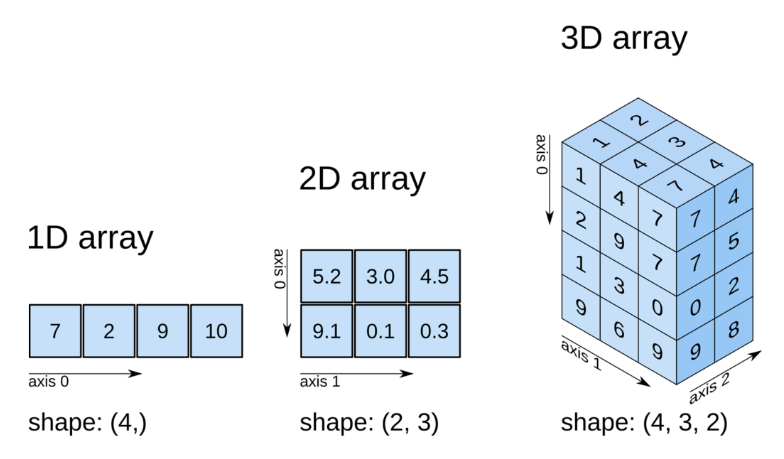
# 각 행렬 또는 각 열별로 데이터를 분석할때는???
# 축이 필요하다! axis를 적어주면 된다.
- axis=0: 배열의 첫 번째 차원을 나타낸다. (행 방향)
- axis=1: 배열의 두 번째 차원을 나타낸다. (열 방향)
- axis=2: 배열의 세 번째 차원을 나타낸다. (깊이 또는 채널 방향)
# 3차원 배열에서 axis=2를 사용하면 배열의 깊이 또는 채널 방향에 따른 연산을 수행할 수 있다. 예를들어, RGB 이미지 데이터를 처리할 때, 각 채널(Red, Green, Blue)에 대한 연산을 axis=2를 사용하여 수행할 수 있다.
# 상단에서 생성하였던 X 값
X = np.random.randint(1, 100, (4,5))
X
array([[74, 46, 91, 68, 83],
[29, 23, 66, 66, 86],
[93, 89, 71, 16, 64],
[ 4, 7, 84, 41, 4]])
# 각 행중 최대값
X.max(axis = 1)
array([91, 86, 93, 84])
# 각 열중 최대값
X.max(axis = 0)
array([93, 89, 91, 68, 86])
# 각 열중 최소값
X.min(axis = 0)
array([ 4, 7, 66, 16, 4])
# 열들의 합계
X.sum(axis = 0)
array([200, 165, 312, 191, 237])
# 열들의 평균값
X.mean(axis = 0)
array([50. , 41.25, 78. , 47.75, 59.25])
# 열드의 표준 편차
X.std(axis = 0)
array([35.29164207, 30.85753555, 9.97496867, 21.19404397, 32.99526481])
* 행으로 실행하고 싶을때는 axis 값을 1로 변경해주면 된다.
# 특정한 데이터 값만 가지고오고 싶을떄 (불린 연산 및 슬라이싱 기능에 대한 간단한 연습)
# X에, 70보다 큰 데이터는 몇개가 있나요??
# 4 x 5 형태의 임의의 데이터 생성
X = np.random.randint(1, 100, (4,5))
X
array([[56, 72, 81, 3, 95],
[20, 99, 64, 54, 28],
[57, 31, 49, 48, 40],
[39, 45, 19, 65, 57]])
# X의 데이터에서 70보다 큰값을 불린 형태로 확인
X > 70
array([[False, True, True, False, True],
[False, True, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False]])
# 70 이상인 요소의 합계 (70이상이 몇개인가?)
(X > 70).sum()
4
# int(True) 함수를 사용하여 Ture 값이 1이라는것을 이용하여 True 데이터 갯수를 sum 함수로 확인 가능
# 특정한 위치의 데이터를 가지고 오고 싶을땐 인덱싱을 이용
a = [1, 2, 3]
a[1] #인덱싱 하여 해당 인수 자리의 값을 가져온다.
2
my_phone = { 'color' : 'red', 'model' : 'iPhone 14', 'year' : 2021 } # 키와 벨류 key : value => item
my_phone['color']
'red'
# X 의 데이터중에서 70보다 큰 데이터만 가져오시오. ** 여러데이터를 한 변수에 저장하는것을 데이터 스트럭쳐
X > 70
array([[False, True, True, False, True],
[False, True, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False]])ㄴ True, False로 표현되는 것이 불린
X[ X > 70]
array([72, 81, 95, 99])
# 간단한 실습 예제를 통한 복습
4 x 4 ndarray 만드세요.
단, 2 에서 32 까지의 순차적 짝수로 채워졌습니다.
X = np.arange(2, 32+1, 2).reshape(4,4)
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
TYPE OF NUMPY ARRAYS
X.shape
(4, 5)MAX AND MIN VALUES AND THEIR INDEX
X.max()
32
# .argmax() => 가장 큰 값의 인덱스 위치를 출력한다. (다차원 배열에서는 상단 좌측부터 0으로 인덱스 카운트가 시작된다.)
X.argmax()
15
# .argmin() => 가장 작은 값의 인덱스 위치를 출력한다.
X.argmin()
# axis 를 사용할경우 각 행 혹은 각 열마다 가장 큰 데이터값이 있는 인덱스 위치를 출력한다.
X.argmax(axis = 1)
array([3, 3, 3, 3], dtype=int64)Accessing Elements Into ndarrays
# 1차원 배열의 인덱스 접근
x = np.random.randint(1, 20, 7)
x
array([ 8, 16, 10, 18, 8, 10, 7])
# 끝에서 순번을 찾을때는 -를 사용할수 있다
x[-3]
8
다차원배열의 인덱스 접근
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
# (1) 행, 열 순서로 , 를 기준으로 위치를 지정하여 접근
X[ 1 , 2 ]
14
# (2) 행, 열을 따로 []를 기준으로 작성하여 접근 가능
X[1][2]
14
다음 게시글에서 계속
'PYTHON LIBRARY > NumPy Library' 카테고리의 다른 글
| Python NumPy로 데이터 분석하기 : Boolean 연산부터 Broadcasting까지 (0) | 2024.04.08 |
|---|---|
| Python NumPy 슬라이싱과 인덱싱 : 효율적인 데이터 접근 방법 ndarray[], copy() 활용 (1) | 2024.04.08 |
| Python NumPy의 기본 함수와 메서드 : 배열 생성부터 형태 변환까지 (0) | 2024.04.04 |
| Python에서 데이터 저장 및 불러오기 : NumPy의 save와 load 함수 사용법 (0) | 2024.04.04 |
| Python과 NumPy 기초 : 다차원 배열과 선형대수학 라이브러리 시작하기 (1) | 2024.04.03 |