NUMPY BASICS
- NumPy는 다차원 배열을 처리할 수 있는 선형대수학(Linear Algebra) 라이브러리입니다.
- 다음이 실행이 안되면 아나콘다프롬프트에서 conda install numpy 를 실행하여 설치합니다.
- 1차원 배열 = 벡터 (Vector) / 2차원 배열 = 행렬 (Matrix)
<1차원 배열의 list를 생성>
score_list = [100, 90, 75, 66, 98]
# 리스트 마지막에 값을 추가할떄 .append 사용
score_list.append(58)
[100, 90, 75, 66, 98, 58]
# 삭제할때는 변수명 앞에 del를 붙여서 사용 ** index 위치를 [] 안에 기재해 줘야함
del score_list[5]
[100, 90, 75, 66, 98]
# 합계
sum(score_list)
428
# 길이
len(score_list)
5
# 평균
sum(score_list) / len(score_list)
85.6
# 타입 확인
type(score_list)
list
<사전 형식의 key : value 값을 가진 1차원 배열 list 생성>
score_dict = { '철수' : 100, '영희' : 90, '길동' : 75 }
# value 값만 확인할 때
score_dict.values()
dict_values([100, 90, 75])
# value 값의 합계
sum(score_dict.values())
265
# 길이
len(score_dict.values())
3
# 평균
sum(score_dict.values()) / len(score_dict.values())
88.33333333333333
# 타입 확인
type(score_dict)
dict
<Numpy 임포트 하기>
import numpy as np
# 넘파이의 1차원 배열로 만드는 방법 : 리스트를 넣어준다.
np.array(score_list)
array([99, 90, 75, 66, 98])
# 변수 지정
x = np.array(score_list)
x
array([99, 90, 75, 66, 98])
# array 변수의 갯수 확인
x.size
5
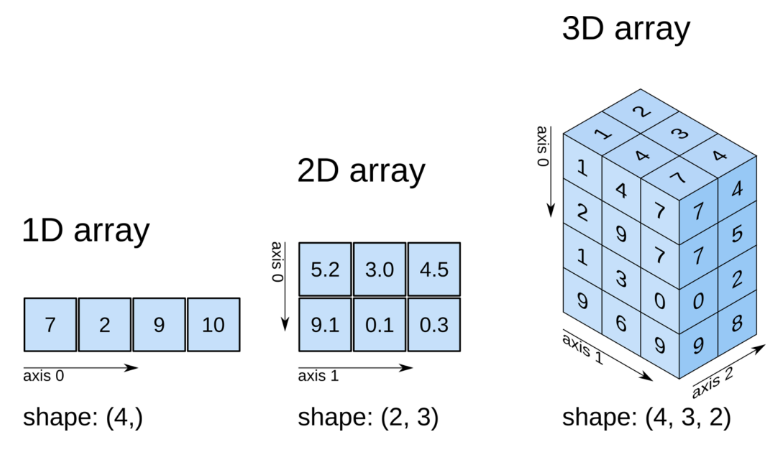
# 넘파이에서 shape 은 배열의 차원(dimension)과 각 차원의 크기(size)를 튜플(tuple) 형태로 반환 (중요)
x.shape
(5,)ㄴ 튜플은 ( x , y ) 형식으로 출력되기 때문에 1차원 배열의 변수일경우 무조건 ( x , ) y 위치가 빈여백으로 출력 된다.
# x 가 저장하고 있는 데이터의 타입은?
x.dtype
dtype('int32')
# 합계
x.sum()
428
# 평균
x.mean()
85.6
# 표준 편차
x.std()
13.032267646115928
<2차원 배열의 array 값 만들기>
X = np.array([[1, 2] , [3, 4]])
X
array([[1, 2],
[3, 4]])
# 1차원 배열과 모두 동일하게 dtype, sum, mean, std 함수는 출력되고,
# .shape 함수 실행시
X.shape
(2, 2)
ㄴ 1차원 배열과 다르게 (X, Y) 형태로 반환되는 것을 볼수 있다.
다음 게시글에서 계속
'PYTHON LIBRARY > NumPy Library' 카테고리의 다른 글
| Python NumPy로 데이터 분석하기 : Boolean 연산부터 Broadcasting까지 (0) | 2024.04.08 |
|---|---|
| Python NumPy 슬라이싱과 인덱싱 : 효율적인 데이터 접근 방법 ndarray[], copy() 활용 (1) | 2024.04.08 |
| Python Numpy로 데이터 분석하기: 최대값, 최소값, 평균 등 기초 통계 및 축(axis)별 연산 (0) | 2024.04.05 |
| Python NumPy의 기본 함수와 메서드 : 배열 생성부터 형태 변환까지 (0) | 2024.04.04 |
| Python에서 데이터 저장 및 불러오기 : NumPy의 save와 load 함수 사용법 (0) | 2024.04.04 |