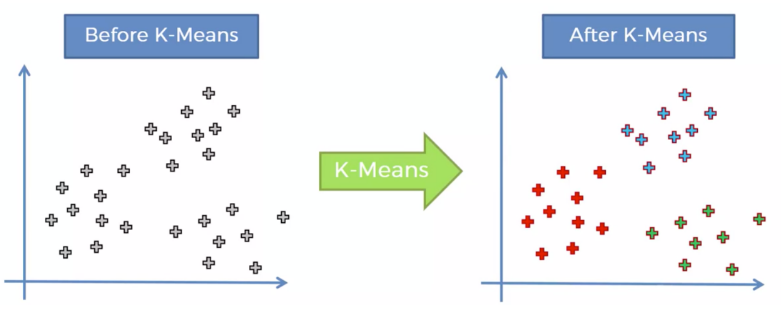
- K-Means Clustering은 비지도 학습 알고리즘 중 하나로, 데이터를 여러 개의 클러스터로 그룹화하는 데 사용된다.- 이 알고리즘의 목표는 데이터 포인트들을 그룹 내에서 가능한 작은 거리의 합계로 클러스터링하는 것! # 이전까지 작성한 Classification(분류)에 KNN, SVM, Decision Tree, Logistic regression# Prediction(예측)에 regression(회귀) 은 모두 Supervised Learnig # Clustering은 모두 Unsupervised Learning 이다. k 개의 그룹을 만든다. 즉, 비슷한 특징을 갖는 것들끼리 묶는것다음을 두개, 세개, 네개 그룹 등등 원하는 그룹으로 만들 수 있다. 알고리즘또다..