
# Pandas를 통해서 가공한 데이터를 가지고 차트로 데이터 시각화를 할수있다
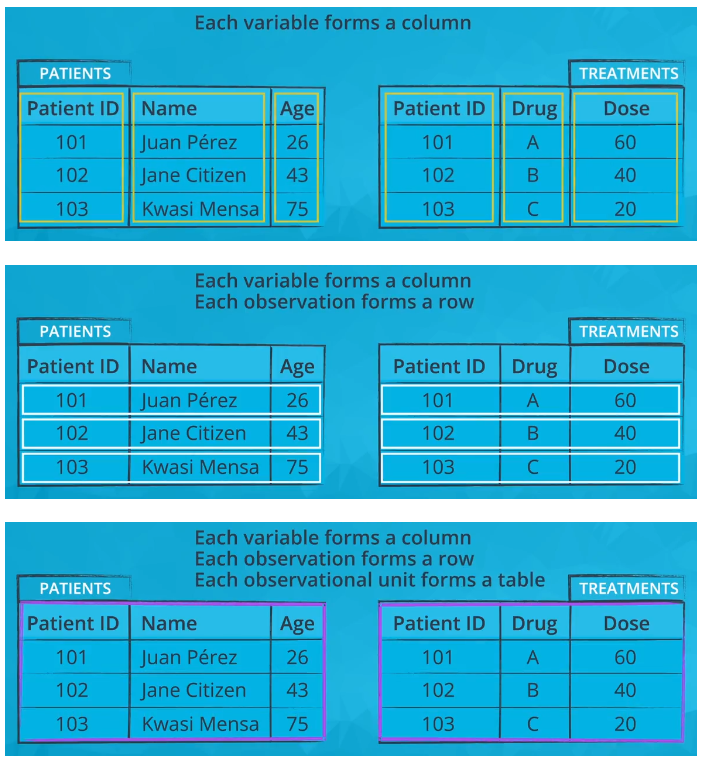
Tidy Data : 데이터 분석과 시각화에 적합한 형식으로 데이터를 정리한 것
- each variable(변수) is a column (컬럼은 형식)
- each observation(하나의 행 => 행은 데이터) is a row
- each type of observational unit is a table
< Matplotlib >
# 파이썬에서 2D 그래픽을 생성하는 데 사용되는 라이브러리
# 다양한 유형의 그래프와 플롯을 만들 수 있으며, 데이터 분석 및 시각화 작업에서 널리 사용된다
# ref : 참고 레퍼런스
https://matplotlib.org/gallery.html#scales
# 가장 많이 사용하는 차트 라이브러리 두가지 => 메트플롯 립, 시본 상단 링크는 해당 차트 설명서
< 가장기본적인 Plot >
# 임포트
import matplotlib.pyplot as plt
import numpy as np
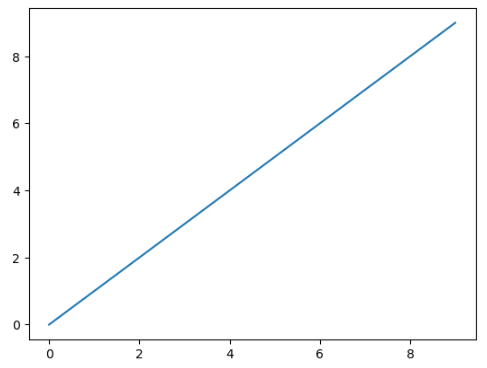
# 간단한 예제를 그려보자 (0,0) (1,1) (2,2) (3,3) (4,4)
# x와 y값이 동일하게 비례하는 데이터의 차트를 그려보자.
x = np.arange(0, 9+1)
x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = x
y
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
plt.plot(x, y)
# 차트를 이미지 파일로 다운받는법 .savefig('파일명.확장자')
plt.savefig('test1.jpg')
# plt.show() 명령어를 적어서 작성한 그래프가 출력되도록 해주어야함.
plt.show()
< Bar Charts >
# 이제 실제 데이터를 가지고 차트를 그려보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
# 새로운 데이터를 가지고와 df 변수로 메모리에 업로드
pd.read_csv('../data/pokemon.csv')
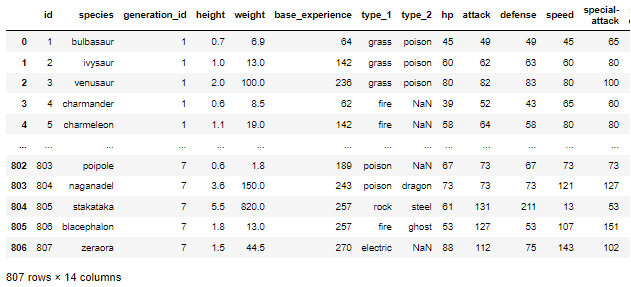
df = pd.read_csv('../data/pokemon.csv')
df
# 항상 새로운 데이터를 불러오면 기본적인 분석을 시행
df.describe()

df.shape
(807, 14)
# 제너레이션 id 값을 확인해보자. => 중복값이 있으므로 카테고리컬 데이터구나 확인
df['generation_id']
0 1
1 1
2 1
3 1
4 1
..
802 7
803 7
804 7
805 7
806 7
Name: generation_id, Length: 807, dtype: int64
df['generation_id'].nunique()
7
df['generation_id'].unique()
array([1, 2, 3, 4, 5, 6, 7], dtype=int64)
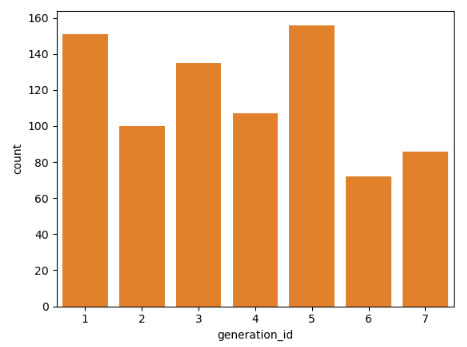
# 제너레이션 id 별로 캐릭터는 몇개씩 있나?
df['generation_id'].value_counts()
generation_id
5 156
1 151
3 135
4 107
2 100
7 86
6 72
Name: count, dtype: int64
< 위의 결과를 차트로 그리는 방법 >
# 특정 컬럼이 카테고리컬 데이터일때,
# 각 value 별로 몇개씩 있는지를 차트로 한번에 나타내고 싶을때
# seaborn 의 countplot 함수 사용.
# seaborn.countplot(data = 사용할 데이터 변수, x= 컬럼)
# df 데어터의 generation_id 컬럼을 차트로 그려줘
sb.countplot(data= df, x= 'generation_id')
plt.show()

# 색 바꾸기
sb.color_palette()

# 우리눈에는 색별로 보이지만 컴퓨터 입장에선 list형식의 숫자데이터임
# 그러므로 원하는 색깔의 인덱스 숫자를 함수뒤에 [ ] 호출해주면됨
# 그린 차트에 붙여넣어야 하므로 변수로 지정하여 원하는 색을 불러옴
base_color = sb.color_palette()[1]
# 파라미터 x 축 뒤에 , color= 로 색 지정
sb.countplot(data=df, x= 'generation_id' , color=base_color)
plt.show()
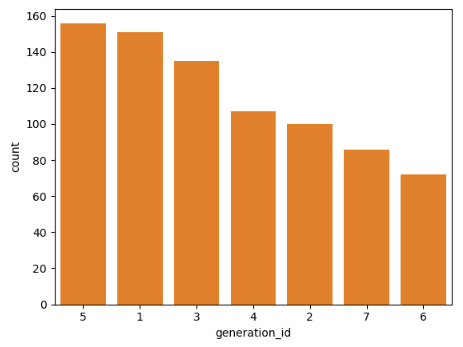
# 차트가 들쑥날쑥하여 정렬 시키고 싶을땐
# 정렬할때는 판다스 시리즈의 인덱스 순서를 그대로 가져와서 사용하면 되기 때문에 value_counts().index를 사용
df['generation_id'].value_counts().index
Index([5, 1, 3, 4, 2, 7, 6], dtype='int64', name='generation_id')
# 해당 순서들의 인덱스 값을 변수로 저장
base_order = df['generation_id'].value_counts().index
# 아까 생성한 바차트 코드의 파라미터안 컬러 뒤에 순서 order 로 정렬
sb.countplot(data=df, x= 'generation_id' , color=base_color , order=base_order)
plt.show()
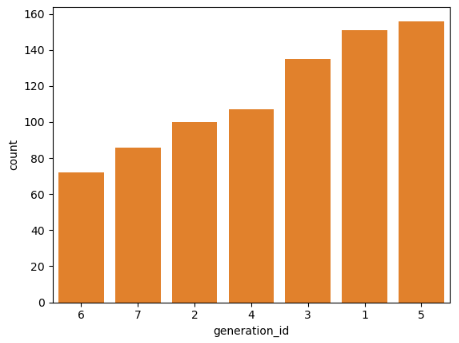
# 차트 정렬을 반대로 하고 싶으면 슬라이싱에서 사용했었던 : : -1 사용( 자주 쓰니 기억할것!!)
reverse_order = base_order[ : : -1]
sb.countplot(data=df, x= 'generation_id' , color=base_color , order=reverse_order)
plt.show()
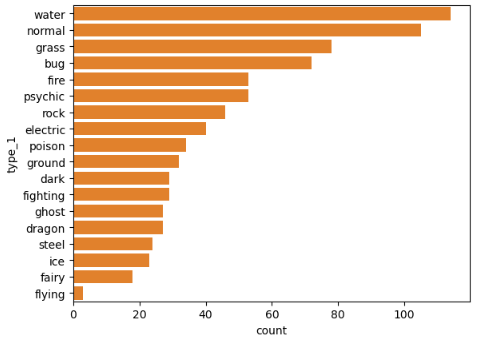
< type_1을 바차트로 작성해보자 >
# (1) 항목이 많아서 x 축 문구가 겹치는 문제 발생 이럴땐 .xticks() 사용
sb.countplot(data= df, x= 'type_1' , color=base_color, order=base_order)
# x 축 문구가 길어 겹치면 문구에 기울기를 줄수 있음
# 문구를 60도 기울여서 출력시켜줘
plt.xticks(rotation=60)
plt.show()

# (2) x축 문구가 넘치니 해결하는 방법 두번째 => x 축을 y 축으로 사용
sb.countplot(data= df, y= 'type_1' , color=base_color, order=base_order)
plt.show()
# type1 종류가 많은데 몇개지?
df['type_1'].nunique()
18
# 범위 지정 : 데이터가 많은, 상위 10개만 차트로 보여주세요. => order 변수에 범위 지정
sb.countplot(data= df, y= 'type_1' , color=base_color, order=base_order[0:9+1])
plt.show()
