반응형
< (1) 영화 추천 API 개발
(DB 데이터 json으로 가져오기) >
# 기본 설정은 이전 Project와 동일!
- 크게 다른점이, 이전 API 들과는 다르게 추천시스템을 이용하게 이전에 DB에서 작업한 테이블을 Colab에 불러와서 데이터 가공을 먼저 진행해 주어야 한다.
# DB를 json 파일로 저장하고 가져오는 방법
- 영화 추천을 위해 movie와 review 테이블의 데이터가 필요
- 원하는 테이블을 우측 클릭 후 Table Data Export Wizard 선택 후, json 형식으로 경로 설정하여 저장
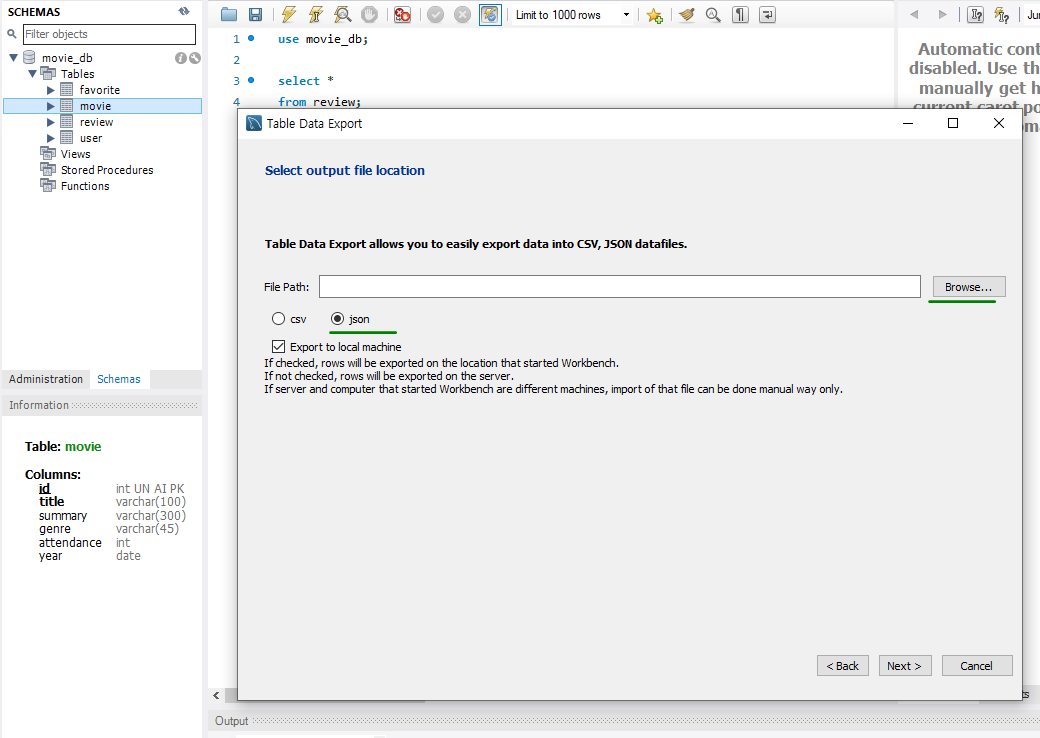
# 저장된 데이터를 구글드라이브에 올려서 코랩으로 실행하거나 코랩 폴더에 옮겨서 작업

ㄴ 데이터 가공후 확인이 필요하기 때문에, MySQL에서 하던 작업을 Colab에서 진행한다고 보면됨
ㄴ 물론 Pandas, Numpy 기능도 활용하고 데이터를 눈으로 보기위한것도 있음
# 해당 파일엔 리스트양이 너무 적어서 그냥 새로운 csv 파일을 다운로드 받아와서 진행
- 상단의 Database 저장하는 방법도 알고있을것!
- 한줄씩 Colab에서 작성하여 실행
### 데이터가 너무 없어서 새로운 데이터로!
movie_df = pd.read_csv('Movie_Id_Titles.csv')
review_df = pd.read_csv('user_rating.csv')
df = pd.merge(movie_df, review_df, on = 'item_id' , how='left')
df = df.pivot_table(index='user_id', columns='title', values='rating')
corr_movie = df.corr(min_periods=50)
my_review = review_df.loc[ review_df['user_id'] == 0, ]
my_review = pd.merge(my_review, movie_df, on='item_id')[['title', 'rating']]
title = my_review['title'][0]
recom_movie = corr_movie[title].dropna().sort_values(ascending=False).to_frame()
recom_movie.columns = ['correlation']
recom_movie['weight'] = recom_movie['correlation'] * my_review['rating'][0]
# 자동으로 해당 유저가준 별점마다 계산되도록 만들어주어야 한다.
# 비어있는 빈 데이터프레임을 만들고,
# 내가 본 영화의 가중치까지 계산해서, 추천영화를 뽑고
# 이 추천영화들을, 위의 빈 데이터프레임에 추가하면 된다.
# 모두 추가한 후에, 정렬한 후, 중봅영화 제거하고, 이미본 영화 제거하면 된다.
movie_list = pd.DataFrame()
for i in np.arange(my_review.shape[0]) :
title = my_review['title'][i]
recom_movie = corr_movie[title].dropna().sort_values(ascending=False).to_frame()
recom_movie.columns = ['correlation']
recom_movie['weight'] = recom_movie['correlation'] * my_review['rating'][i]
movie_list = pd.concat([movie_list, recom_movie])
# weight 컬럼으로 정렬
movie_list.sort_values(by='weight', ascending=False, inplace=True)
# 내가 이미 본 영화는 추천에서 제외한다.
for title in my_review['title'] :
if title in movie_list.index :
movie_list.drop(title, axis = 0, inplace=True)
# 중복된 영화는, 웨이트의 최대값으로 계산해서, 중복제거한다.
movie_list = movie_list.groupby('title')['weight'].max().sort_values(ascending=False).head(5)
movie_list.to_frame()
movie_list.to_dict('records')
다음 게시글로 계속~!
728x90
반응형
'API 개발 > API 개발 Project' 카테고리의 다른 글
| API Project : (1) SNS 서비스 개발 (기본 세팅부터 진행!) (0) | 2024.05.29 |
|---|---|
| API Project : (2) 영화 추천 API 개발 (대용량 파일 Docker 서버 배포) (1) | 2024.05.29 |
| API Project : 메모앱 API 서버 개발 (0) | 2024.05.29 |
| API Project : 레시피 생성 API 개발 (0) | 2024.05.29 |
| API Project : 전체 개발 과정 정리 (0) | 2024.05.29 |